Un aperçu de HTTP
HTTP est un protocole qui permet de récupérer des ressources telles que des documents HTML. Il est à la base de tout échange de données sur le Web. C'est un protocole de type client-serveur, ce qui signifie que les requêtes sont initiées par le destinataire (qui est généralement un navigateur web). Un document complet est construit à partir de différents sous-documents qui sont récupérés, par exemple du texte, des descriptions de mise en page, des images, des vidéos, des scripts et bien plus.
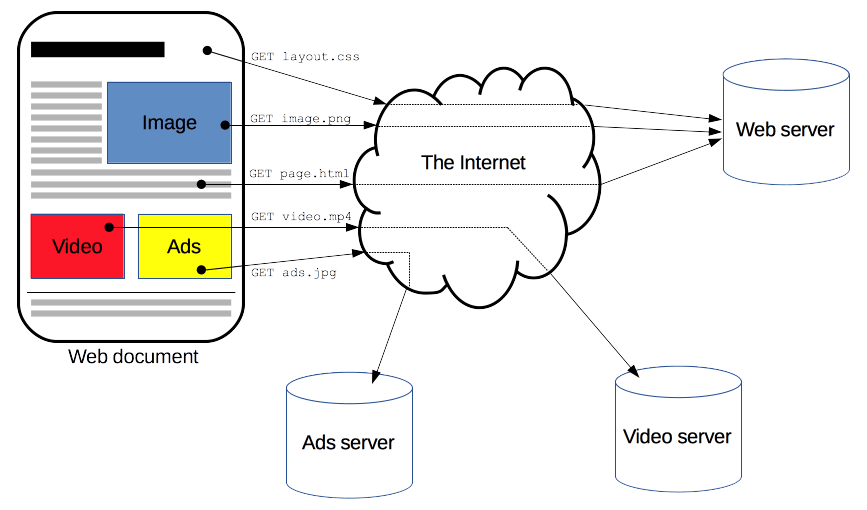
Les clients et serveurs communiquent par l'échange de messages individuels (en opposition à un flux de données). Les messages envoyés par le client, généralement un navigateur web, sont appelés des requêtes et les messages renvoyés par le serveur sont appelés réponses.
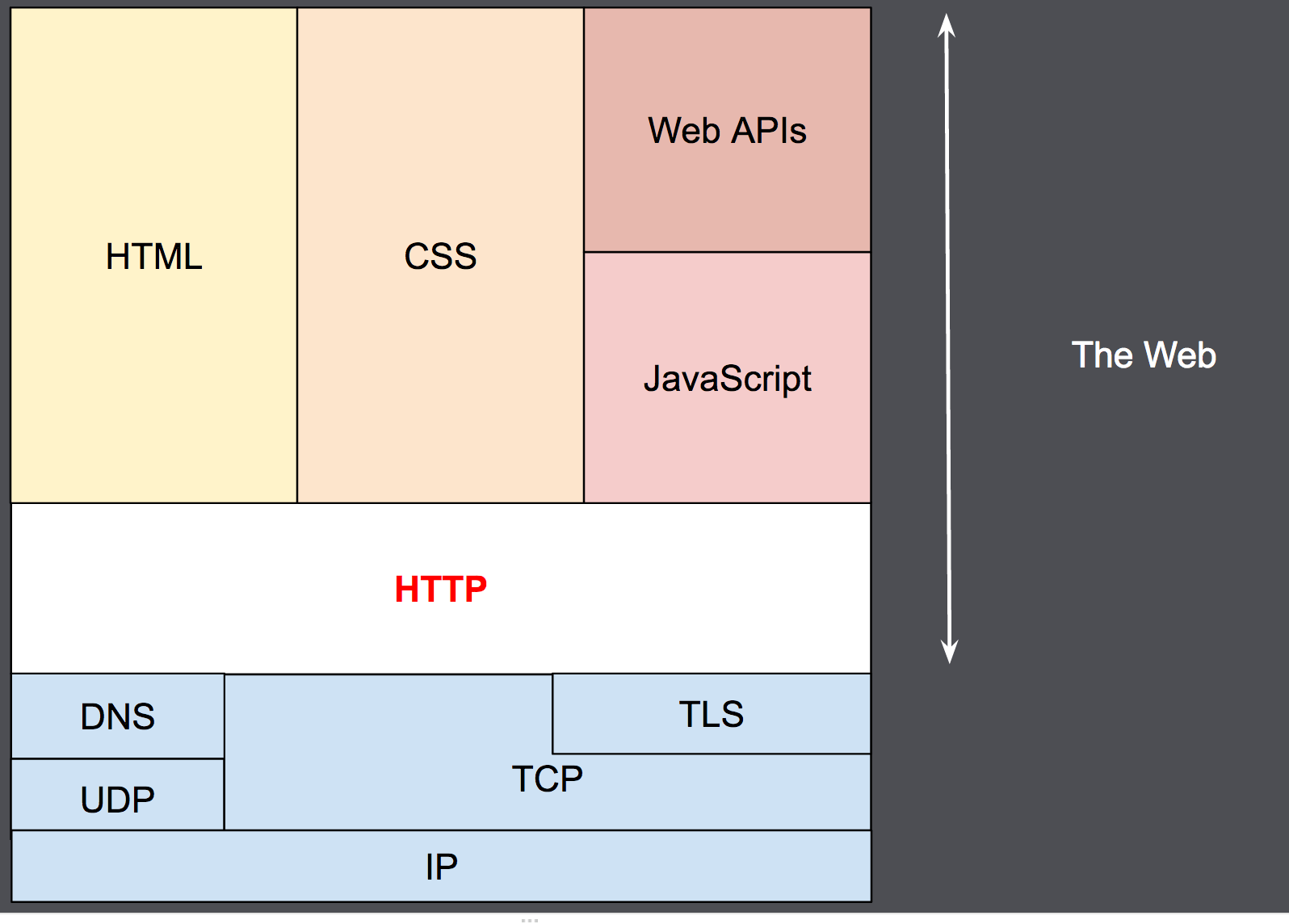 Conçu au début des années 1990, HTTP est un protocole extensible qui a évolué au cours du temps. C'est un protocole de la couche application dont les données transitent via TCP ou à travers une connexion TCP chiffrée avec TLS. En théorie, tout protocole de transport fiable pourrait être utilisé. En raison de son extensibilité, il n'est pas seulement utilisé pour récupérer des documents, mais aussi pour des images, des vidéos ou bien pour renvoyer des contenus vers des serveurs, comme des résultats de formulaires HTML. HTTP peut aussi être utilisé pour récupérer des parties de documents pour mettre à jour à la demande des pages web.
Conçu au début des années 1990, HTTP est un protocole extensible qui a évolué au cours du temps. C'est un protocole de la couche application dont les données transitent via TCP ou à travers une connexion TCP chiffrée avec TLS. En théorie, tout protocole de transport fiable pourrait être utilisé. En raison de son extensibilité, il n'est pas seulement utilisé pour récupérer des documents, mais aussi pour des images, des vidéos ou bien pour renvoyer des contenus vers des serveurs, comme des résultats de formulaires HTML. HTTP peut aussi être utilisé pour récupérer des parties de documents pour mettre à jour à la demande des pages web.
Composants des systèmes basés sur HTTP
HTTP est un protocole client-serveur : les requêtes sont envoyées par une entité : l'agent utilisateur (ou le proxy qui agit au nom de celui-ci). La majorité du temps, l'agent utilisateur est un navigateur web, mais cela peut-être n'importe quoi, un robot qui analyse le Web pour remplir et maintenir l'index d'un moteur de recherche est un exemple d'agent utilisateur.
Chaque requête individuelle est envoyée au serveur, qui la traite et fournit une réponse. Entre cette requête et la réponse se trouve de nombreuses entités qu'on désignera de façon générique sous le terme proxies. Celles-ci exécutent différentes opérations et agissent comme passerelles ou comme caches par exemple.

En réalité, il y a plus d'un ordinateur entre un navigateur et le serveur qui traite la requête : il y a les routeurs, les modems et bien plus. Grâce à la construction en couche du Web, ces intermédiaires sont cachés dans les couches réseau et transport. HTTP est bâti sur la couche applicative. Bien qu'elles puissent s'avérer importantes lorsqu'il s'agit de diagnostiquer des problèmes réseau, les couches inférieures ne sont pas pertinentes ici pour décrire HTTP.
Le client : l'agent utilisateur
L'agent utilisateur correspond à n'importe quel outil qui agit pour le compte de l'utilisateur. Ce rôle est principalement rempli par le navigateur web ; les exceptions étant les programmes utilisés par des ingénieurs et développeurs web pour le débogage de leurs applications.
Le navigateur est toujours celui qui initie la requête. Il ne s'agit jamais du serveur (bien que certains mécanismes aient été ajoutés au cours des années afin de simuler les messages initiés par un serveur).
Pour afficher une page web, le navigateur envoie une requête initiale pour récupérer le document HTML depuis la page. Ensuite, il analyse le fichier et récupère les requêtes additionnelles qui correspondent aux scripts, aux informations de mise en page (CSS) et les sous-ressources contenues dans la page (généralement des images et des vidéos). Le navigateur web assemble alors ces ressources pour présenter un document complet à l'utilisateur : c'est la page web. Les scripts exécutés par le navigateur peuvent permettre de récupérer plus de ressources par la suite afin de mettre à jour la page web.
Une page web est un document hypertexte. Cela signifie que certaines parties sont des liens qui peuvent être activés (généralement avec un clic de souris) afin de récupérer une nouvelle page web, permettant à l'utilisateur de diriger son agent utilisateur et de naviguer sur le Web. Le navigateur traduit ces instructions en requêtes HTTP et interprète les réponses HTTP pour présenter une réponse claire à l'utilisateur.
Le serveur web
De l'autre côté du canal de communication, on trouve le serveur qui sert le document demandé par le client. Bien qu'on présente virtuellement le serveur comme un seul ordinateur, en réalité, il peut s'agir d'un ensemble de serveurs se répartissant la charge (load balancing) ou d'une architecture logicielle complexe qui interroge d'autres serveurs (par exemple un cache, un serveur de base de données, serveur d'e-commerce…), qui génèrent totalement ou partiellement le document à la demande.
D'une part, un serveur n'est pas nécessairement une machine unique et d'autre part, plusieurs serveurs peuvent être hébergés sur une même machine. Avec HTTP/1.1 et l'en-tête Host, ils peuvent également partager la même adresse IP.
Les proxys
Entre le navigateur Web et le serveur, de nombreux ordinateurs et machines relaient les messages HTTP. En raison de la structure en couches superposées des technologies web, la plupart des opérations au niveau du transport, du réseau ou au niveau physique sont transparents pour la couche HTTP, ce qui peut avoir un impact significatif sur les performances. Les opérations au niveau de la couche applicative sont généralement appelées proxy. Ceux-ci peuvent être transparents ou non (en changeant les requêtes qui passent par eux), et peuvent effectuer de nombreuses tâches :
- mettre en cache (le cache peut alors être public ou privé, comme le cache du navigateur)
- filtrer (comme un antivirus, contrôle parental…)
- répartir la charge (pour permettre à de multiples serveurs de servir différentes requêtes)
- authentifier (pour contrôler l'accès à différentes ressources)
- effectuer la journalisation (permettant le stockage des informations d'historiques)
Principaux aspects d'HTTP
HTTP est simple
Même s'il est devenu plus complexe avec l'arrivée d'HTTP/2 et l'encapsulation des messages HTTP dans des trames, HTTP est généralement conçu pour être simple et lisible par un humain. Les messages HTTP peuvent être lus et compris par des humains, ce qui facilite les tests des développeurs et réduit la complexité pour les débutants.
HTTP est extensible
À partir de HTTP/1.0, les en-têtes HTTP permettent d'étendre facilement le protocole et de mener des expérimentations avec celui-ci. De nouvelles fonctionnalités peuvent même être introduites par un simple accord entre le client et le serveur à propos de la sémantique des nouveaux en-têtes.
HTTP est sans état, mais pas sans session
HTTP est sans état : il n'y a pas de lien entre deux requêtes qui sont effectuées successivement sur la même connexion. Cela devient très rapidement problématique lorsque les utilisateurs veulent interagir avec une page de façon cohérente, par exemple avec un panier d'achat sur un site de commerce en ligne. Bien que le cœur d'HTTP soit sans état, les cookies HTTP permettent l'utilisation de sessions avec des états. En utilisant l'extensibilité par les en-têtes, des cookies HTTP sont ajoutés aux flux et permettent la création d'une session sur chaque requête HTTP pour partager un même contexte, ou un même état.
HTTP et les connexions
Une connexion est contrôlée au niveau de la couche transport et est donc fondamentalement hors de portée d'HTTP. Bien que HTTP ne nécessite pas un protocole de transport basé sur une connexion, le protocole doit être fiable ou empêcher la perte de messages (donc gérer au minimum la remontée des erreurs). Parmi les deux protocoles de transport les plus courants sur Internet, TCP est fiable et UDP ne l'est pas. HTTP s'appuie sur le standard TCP, qui est basé sur la connexion, même si une connexion n'est pas toujours nécessaire.
HTTP/1.0 ouvre une connexion TCP pour chaque échange requête/réponse, ce qui introduit deux défauts majeur : l'ouverture d'une connexion nécessite plusieurs allers-retours, ce qui est lent mais devient plus efficace lorsque plusieurs messages sont envoyés et envoyés régulièrement. On dit aussi que les connexions qui restent chaudes sont plus efficaces que les communications froides.
Afin de réduire ces défauts, HTTP/1.1 introduit le pipelining (qui s'est avéré difficile à mettre en œuvre) et les connexions persistantes : la connexion TCP sous-jacente peut être partiellement contrôlée en utilisant l'en-tête Connection. HTTP/2 va plus loin en multiplexant des messages sur une seule connexion, ce qui aide à maintenir la connexion chaude et plus efficace
Des expérimentations sont en cours afin de concevoir un protocole de transport plus adapté pour HTTP. Par exemple, Google expérimente QUIC, construit sur UDP pour fournir un protocole de transport plus fiable et efficace.
Ce qui peut être contrôlé par HTTP
Au fil du temps, la nature extensible de HTTP a permis de mieux contrôler le Web et d'y ajouter de nouvelles fonctionnalités. Les méthodes de cache ou d'authentification sont des fonctions qui furent gérées dès le début de HTTP tandis que la possibilité de lever la contrainte d'unicité de l'origine ne fut introduite qu'à partir des années 2010.
Voici une liste de fonctionnalités courantes, qui peuvent être contrôlées grâce à HTTP.
- Cache La façon dont les documents sont mis en cache peut être contrôlée par HTTP. Le serveur peut indiquer aux proxys et aux clients ce qu'ils doivent mettre en cache et pour combien de temps. Le client peut indiquer aux proxys de cache intermédiaires d'ignorer le document qui est stocké.
- Lever la contrainte d'origine unique Pour éviter l'espionnage et d'autres invasions dans la vie privée, les navigateurs web imposent une séparation stricte entre les sites web. Seules les pages de la même origine peuvent accéder à toutes les informations d'une page web. Bien que cette contrainte soit un fardeau pour le serveur, les en-têtes HTTP peuvent assouplir cette séparation stricte du côté serveur, en permettant à un document de devenir un patchwork d'informations en provenance de différents domaines (il existe même des raisons de sécurité de procéder ainsi).
-
Authentification
Certaines pages peuvent être protégées de sorte que seuls certains utilisateurs puissent y accéder. Une authentification simple peut être fournie par HTTP, soit en utilisant l'en-tête
WWW-Authenticateet des en-têtes similaires, soit en définissant une session spécifique grâce à des cookies HTTP. - Proxys et tunnels (en-US) Les serveurs et/ou les clients sont souvent situés sur des intranets et cachent leur véritable adresse IP à d'autres. Les requêtes HTTP passent ensuite par des proxys pour traverser cette barrière de réseau. Tous les proxys ne sont pas des proxys HTTP. Le protocole SOCKS, par exemple, fonctionne à un niveau inférieur. D'autres, comme FTP, peuvent être manipulés par ces proxys.
- Sessions L'utilisation de cookies HTTP permet de lier les requêtes à l'état du serveur. Cela crée des sessions, malgré le fait que HTTP soit, au sens strict, un protocole sans état. Ceci est utile non seulement pour les paniers de commerce électronique en ligne, mais aussi pour tout site permettant une configuration de l'utilisateur.
Flux HTTP
Lorsqu'un client veut communiquer avec un serveur, que ce soit avec un serveur final ou un proxy intermédiaire, il réalise les étapes suivantes :
- Il ouvre une connexion TCP : la connexion TCP va être utilisée pour envoyer une ou plusieurs requêtes et pour recevoir une réponse. Le client peut ouvrir une nouvelle connexion, réutiliser une connexion existante ou ouvrir plusieurs connexions TCP vers le serveur.
- Il envoie un message HTTP : les messages HTTP (avant HTTP/2) sont lisibles par les humains. Avec HTTP/2, ces simples messages sont en-capsulés dans des trames, rendant la lecture directe impossible, mais le principe reste le même.
http
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - Il lit la réponse envoyée par le serveur :
http
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html... (suivi des 29769 octets de la page web demandée) - Il ferme ou réutilise la connexion pour les requêtes suivantes.
Si le pipeline HTTP est activé, plusieurs demandes peuvent être envoyées sans attendre que la première réponse soit entièrement reçue. Le pipeline HTTP s'est révélé difficile à implémenter dans les réseaux existants où de vieux logiciels coexistent avec des versions modernes. Le pipeline HTTP a été remplacé dans HTTP/2 par des requêtes de multiplexage plus robustes dans les trames.
Les messages HTTP
Les messages HTTP/1.1 et ceux des versions précédentes d'HTTP sont lisibles par des humains. Avec HTTP/2, ces messages sont intégrés dans une nouvelle structure binaire, une trame, ce qui permet des optimisations telles que la compression des en-têtes et le multiplexage. Même si seule une partie du message HTTP d'origine est envoyée dans cette version d'HTTP, la sémantique de chaque message est inchangée et le client reconstitue (virtuellement) la requête HTTP/1.1 d'origine. Il est donc utile de comprendre les messages HTTP/2 au format HTTP/1.1.
Il existe deux types de messages HTTP, les requêtes et les réponses, chacun ayant son propre format.
Requêtes
Un exemple de requête HTTP :
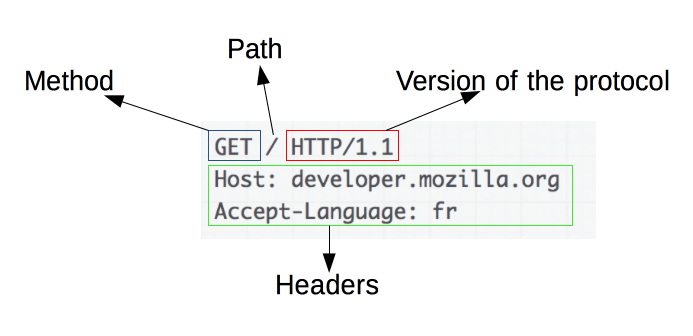
Une requête comprend les éléments suivants :
- Une méthode HTTP : généralement un verbe tel que
GET,POSTou un nom commeOPTIONSouHEADqui définit l'opération que le client souhaite effectuer. Par exemple, un client souhaite accéder à une ressource (en utilisant GET) ou téléverser le résultat d'un formulaire HTML (en utilisantPOST), bien que d'autres opérations puissent être nécessaires dans d'autres cas. - Le chemin de la ressource à extraire : l'URL de la ressource à laquelle on a retiré les éléments déductibles du contexte, par exemple le protocole (http://), le domaine (ici .mozilla.org), ou le port TCP (ici 80).
- La version du protocole HTTP.
- Les en-têtes optionnels qui transmettent des informations supplémentaires pour les serveurs.
- Ou un corps, pour certaines méthodes comme POST, semblable à ceux dans les réponses, qui contiennent la ressource envoyée.
Réponses
Un exemple de réponse :
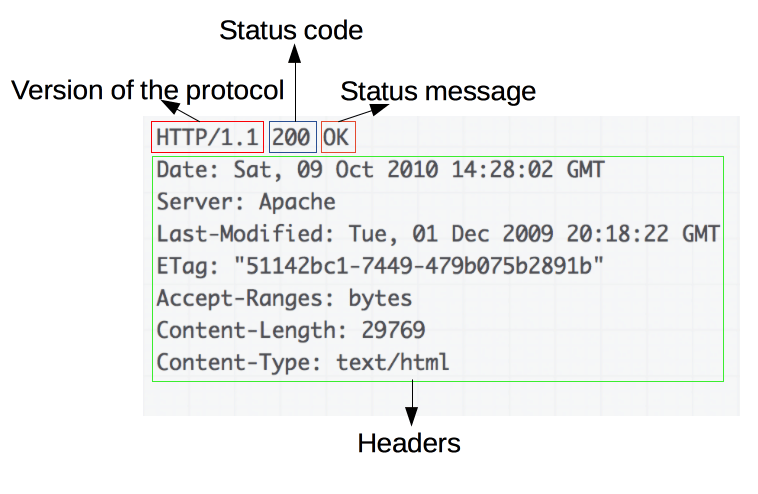
Une réponse comprend les éléments suivants:
- La version du protocole HTTP qu'elle suit
- Un code de statut, qui indique si la requête a réussi ou non.
- Un message de statut qui est une description rapide, informelle, du code de statut
- Les en-têtes HTTP, comme pour les requêtes.
- Éventuellement un corps contenant la ressource récupérée.
Les APIs basées sur HTTP
L'API la plus utilisée se basant sur HTTP est l'API XMLHttpRequest qui permet d'échanger des données entre un agent utilisateur user agent et un serveur.
Une autre API, server-sent events, est un service unidirectionnel permettant à un serveur d'envoyer des notifications au client, en se basant sur le protocole HTTP. À l'aide de l'utilisation de l'interface EventSource, le client ouvre une connexion et initie un gestionnaire d'évènements. Le navigateur convertit alors automatiquement les messages du flux HTTP en objets de type Event, pour ensuite les déléguer au gestionnaire d'évènements qui se sont abonnés à ce type d'évènement. Dans le cas où le type est inconnu ou si aucun gestionnaire typé n'a été défini, ils sont délivrés au gestionnaire d'évènements onmessage (en-US).
Conclusion
HTTP est un protocole extensible, facile d'utilisation. La structure client-serveur, combinée avec la possibilité d'ajouter simplement des en-têtes, permet à HTTP de progresser au fur et mesure de l'ajout de nouvelles fonctionnalités sur le Web.
Bien que HTTP/2 ajoute de la complexité, en englobant les messages HTTP dans des trames pour améliorer les performances, la structure de base des messages est restée la même depuis HTTP/1.0. Le flux de session reste simple, ce qui lui permet d'être étudié et débogué avec un simple moniteur de message HTTP.