ページの生成: ブラウザーの動作の仕組み
ユーザーは、読み込みが速く、スムーズに操作できるコンテンツを、ウェブで体験することを求めています。したがって、開発者はこれらふたつの目標を達成するために努力しなければいけません。
どうやってパフォーマンスそして体感パフォーマンスを改善するか理解するためには、ブラウザーがどのように動作するかを理解することが役に立ちます。
概要
速いサイトはより良いユーザー体験をもたらします。ユーザーは読み込みが速く、スムーズに操作できるコンテンツを体験することを求め、期待しています。
ウェブのパフォーマンスにおける主要な 2 つの課題は、レイテンシーに関わる問題と、ほとんどのブラウザーが単一のスレッドであるという事実に関わる問題です。
レイテンシーは、高速に読み込むページを確実に提供するための最大の脅威です。ユーザーがリクエストされた情報をすばやく取得できるように、サイトの読み込みを可能な限り速くすること、少なくとも超高速で読み込んでいるように見せることが、開発者の目標です。ネットワークレイテンシーは、コンピューターにバイト列を転送するのにかかる時間のことです。ウェブパフォーマンスとは、ページをできるだけすばやく読み込ませるために私たちがしなければならないことです。
多くの場合、ブラウザーはシングルスレッドだと考えられます。つまり、一つの仕事を最初から最後までやり遂げた後に、次の仕事に取り掛かるのです。スムーズな操作を実現しようとする開発者のゴールは、滑らかなスクロール、タッチ操作への反応など、期待通りのサイトの操作を実現することです。メインスレッドが全ての処理を時間内に完了し、その上でユーザーの操作を常にハンドリングできるよう保証するために、描画時間が鍵となります。ブラウザーがシングルスレッドであることによる特性を理解し、メインスレッドの責務を最小限に抑え、可能かつ適切な場合に、描画のスムーズさと操作への即時の反応を実現することで、ウェブのパフォーマンスが改善されます。
ナビゲーション
ナビゲーションはウェブページを読み込むための最初の一歩です。ユーザーが URL をアドレスバーに入力したり、リンクをクリックしたり、またはフォームを送信したり、ページをリクエストするたびにナビゲーションが発生します。
ウェブのパフォーマンスにおける目標の 1 つは、ナビゲーションが完了するまでの時間を最小限にすることです。理想的な条件下において、一般的にこの時間が長すぎることはありませんが、レイテンシーと帯域幅が遅延を引き起こす邪魔者になる場合があります。
DNS 検索
ウェブページへのナビゲーションの最初の一歩は、ページのアセットがどこにあるか見つけることです。https://example.com へアクセスする場合、その HTML のページは IP アドレスが 93.184.216.34 のサーバーに存在します。これまでに一度もそのサイトを訪れたことがなかった場合、DNS 検索が必要になります。
ブラウザーが DNS 検索をリクエストし、そのリクエストは最終的にネームサーバーによって処理され、ネームサーバーが IP アドレスを返します。この最初のリクエストの後、多くの場合その IP アドレスはしばらくの間キャッシュされ、ネームサーバーへ再接続する代わりにキャッシュから IP アドレスを取得することによって、後続するリクエストの速度を向上します。
DNS 検索は、一般的に、1 回のページ読み込みの中でホスト名ごとに 1 回だけ必要になります。しかし、DNS 検索は要求されたページが参照するユニークなホストネームそれぞれに対して実行が必要です。必要なフォントや画像、スクリプト、広告、メトリクスのそれぞれが異なるホスト名を持っている場合は、それぞれに対して DNS 検索が必要です。
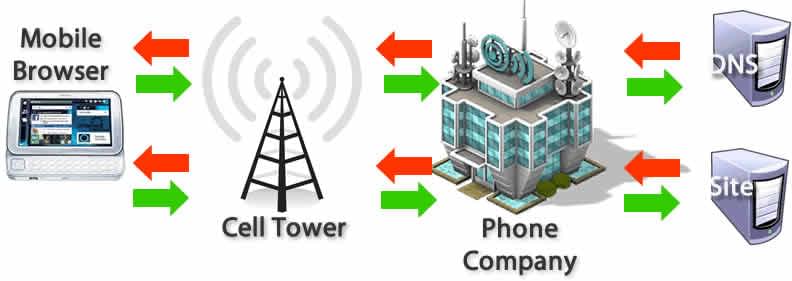
これはとくにモバイルネットワークにおいてパフォーマンス上の問題になる可能性があります。ユーザーがモバイルネットワークを利用している場合、DNS 検索は、権威 DNS サーバーへ到達するために、電話機から基地局へ送信される必要があります。電話機と基地局、そしてネームサーバー間の距離によって重大な遅延が発生する場合があります。
TCP ハンドシェイク
IP アドレスが判明すると、ブラウザーは TCP 3 ウェイハンドシェイクを通じてサーバーとのコネクションを設定します。この仕組みは、通信を意図する 2 つの主体が—この場合はブラウザーとウェブサーバーが—、データを送信する前に、多くの場合 HTTPS を用いて、ネットワーク TCP ソケットコネクションのパラメーターを交換できるよう設計されています。
TCP の 3 ウェイハンドシェイクは、しばしば、"SYN-SYN-ACK"、より正確には SYN、SYN-ACK、ACK と呼ばれます。これは 2 つのコンピューターの間で TCP のセッションを開始するために、TCP によって 3 つのメッセージが送受信されることを表します。つまり、これはそれぞれのサーバーの間で 3 回以上のメッセージのやりとりが必要であり、そのためのリクエストが生成されなければいけないことを意味しています。
TLS ネゴシエーション
HTTPS によって確立される安全なコネクションでは、もう 1 つのハンドシェイクが必要です。このハンドシェイク、より正確に言うと TLS ネゴシエーションは、通信の暗号化に使用する暗号の種類を決定し、サーバーを認証し、実際のデータ送信が始まる前に安全な通信の準備を整えます。この処理は、コンテンツのリクエストを実際に送信する前に、さらに 5 回のラウンドトリップを必要とします。
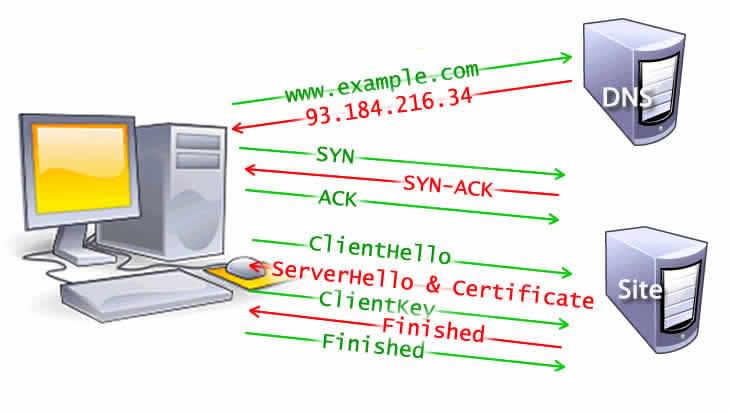
通信を安全にするためにページ読み込みの時間が追加されますが、ブラウザーとサーバーの間で送信されるデータが第三者に解読されないという安全な通信は、レイテンシーに見合う価値があるものです。
8 回のサーバーへのラウンドトリップを経て、ブラウザーはようやくリクエストを送ることができます。
レスポンス
ウェブサーバーへのコネクションが確立されると、ブラウザーはユーザーに代わって最初の HTTP GET リクエストを送信します。ウェブサイトであれば、多くの場合その対象は HTML ファイルです。リクエストを受け取ったサーバーは、適当なレスポンスヘッダーと HTML のコンテンツを返します。
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<title>My simple page</title>
<link rel="stylesheet" href="styles.css" />
<script src="myscript.js"></script>
</head>
<body>
<h1 class="heading">My Page</h1>
<p>A paragraph with a <a href="https://example.com/about">link</a></p>
<div>
<img src="myimage.jpg" alt="image description" />
</div>
<script src="anotherscript.js"></script>
</body>
</html>
この最初のリクエストへのレスポンスは、受信データの最初のバイト (First Byte) を含んでいます。Time to First Byte (TTFB) は、ユーザーがリクエストを実行した時点から—たとえば、リンクをクリックした時点から— HTML の最初のパケットを受信するまでの時間を表します。コンテンツの最初のかたまり (Chunk) は一般的に 14KB のデータです。
上記のサンプルコードでは、リクエストされたコンテンツは明らかに 14KB より小さいですが、後述するように、リンクされたリソースは、ブラウザーの構文解析がそのリンクにたどり着くまでリクエストされることはありません。
輻輳制御 / TCP スロースタート
TCPパケットは送信中にセグメントに分割されます。TCP はパケットの順序を保証しているため、サーバーは一定数のセグメントを送信した後、クライアントから ACK パケットという形で肯定応答を受け取らなければなりません。
各セグメントが終わるたびにサーバーが ACK を待つと、クライアントからの ACK が頻発することになり、たとえ低負荷のネットワークであっても、送信時間が長くなる可能性があります。
一方で、一度に多くのセグメントを送信しすぎると、混雑したネットワークではクライアントがセグメントを受信できず、長い時間に渡って ACK を返し続けることになり、サーバーはセグメントを再送し続けなければならないという問題が発生します。
送信セグメント数のバランスをとるために、 TCP スロースタート (en-US)アルゴリズムを使用することで、最大ネットワーク帯域幅が決定できるまで送信データ量を徐々に増加させ、ネットワーク負荷が高い場合は送信データ量を縮小することができます。
送信するセグメント数は輻輳ウィンドウ (CWND) の値で制御でき、1、2、4、または 10 MSS に初期化できます(MSS はイーサネットプロトコルでは 1500 バイトです)。この値は送信するバイト数で、それを受信するとクライアントは ACK を送信しなけれ ばなりません。
ACK を受信した場合、CWND 値は 2 倍になり、サーバーは次にもっと多くのセグメントを送信できるようになります。代わりに ACK を受け取らなかった場合、 CWND 値は半分になります。この仕組みは、セグメントの送りすぎと少なすぎのバランスをとるものです。
構文解析
データの最初のかたまりを受け取ると、ブラウザーは受信した情報の構文解析を始めることができます。構文解析は、ネットワークから受信したデータを DOM と CSSOM に変換するステップです。DOM と CSSOM は、レンダラーがページを画面へ描画するために利用されます。
DOM はブラウザー向けのマークアップの内部的な表現です。DOM は外部に公開されており、JavaScript の様々な API を通じて操作できます。
ブラウザーは、リクエストしたページの HTML が最初の 14KB のパケットより大きかった場合でも、手元にあるデータに基づいて構文解析を開始し、サイトを描画しようとします。これは、ウェブのパフォーマンスを最適化する時に、ブラウザーがページの描画を始めるために必要なすべてのデータ、あるいは少なくともページのテンプレート (最初の描画に必要となる CSS と HTML) を最初の 14KB に含めることが重要となる理由です。何か 1 つでも画面に描画を行うには、その前に HTML と CSS、JavaScript が解釈されなければいけません。
DOM ツリーの構築
クリティカルレンダリングパス (en-US)の 5 つのステップを説明します。
最初のステップは HTML のマークアップを処理し、DOM ツリーを構築することです。HTML の構文解析は、トークン化とツリーの構築に分かれます。HTML のトークンは開始タグと終了タグ、属性の名前と値を含みます。文書が正しく構成されていれば構文解析は単純で、速度も速くなります。パーサーはトークン化された入力情報を文書ツリーを構成する文書に変換します。
DOM ツリーは文書のコンテンツを表します。 <html> 要素は最初の要素であり、文書ツリーのルートノードとなります。ツリーには、異なる要素同士の関係と階層構造が反映されます。他の要素の中に含まれる要素は子要素となります。 DOM ノードの数が増えるほど、 DOM ツリーの構築にかかる時間は長くなります。
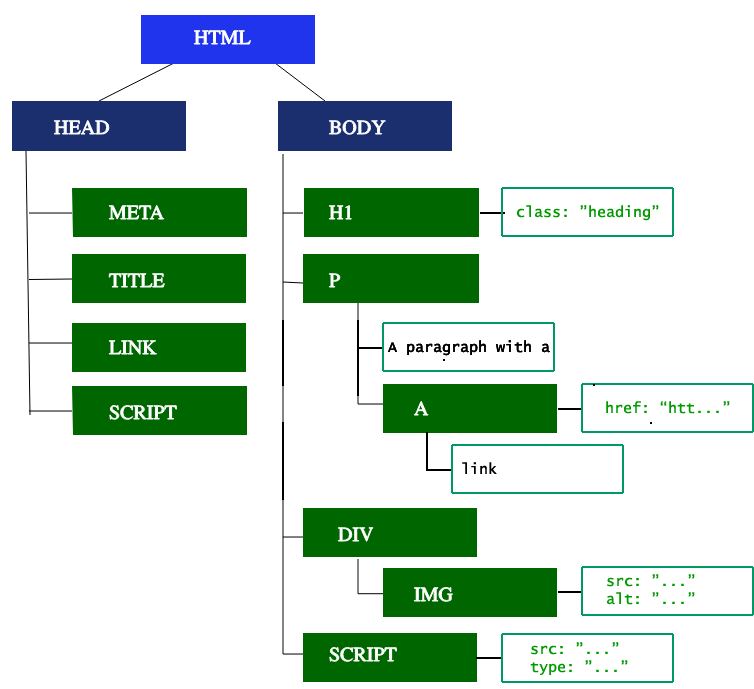
パーサーが画像のようなノンブロッキングリソースを発見した場合、ブラウザーはそのリソースをリクエストし、そのまま構文解析を継続します。CSS ファイルに遭遇した場合も構文解析を継続できます、しかし async または defer 属性がない <script> 要素はレンダリングをブロックし、HTML の構文解析を停止します。ブラウザーの事前読み込みスキャナーがブロックの時間を減らしますが、それでも過度のスクリプトの使用は重大なボトルネックになり得ます。
事前読み込みスキャナー
ブラウザーが DOM ツリーを構築する間はそのプロセスがメインスレッドを占有します。その間に事前読み込みスキャナーが処理可能なコンテンツを解釈し、CSS や JavaScript、ウェブフォントのような優先度の高いリソースのリクエストを行います。事前読み込みスキャナーのおかげで、リクエストするべき外部リソースへの参照をパーサーが見つけるのを待たなくて良くなります。バックグラウンドでリソースを取得するため、メインの HTML パーサーが該当のアセットにたどり着いた時には、すでにそれらのリソースが転送中あるいはダウンロード済みになっています。事前読み込みスキャナーによる最適化によりブロッキングを減らすることができます。
<link rel="stylesheet" href="styles.css" />
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description" />
<script src="anotherscript.js" async></script>
この例では、メインスレッドが HTML と CSS を解釈している間に、事前読み込みスキャナーがスクリプトと画像を探索し、それらのダウンロードを開始します。これらの過程をスクリプトがブロックしないようにするには、 async 属性を付加するか、あるいはスクリプトの解釈と実行順が重要である場合には defer 属性を付加してください。
CSS の取得は HTML の構文解析あるいはダウンロードをブロックしません。しかし JavaScript の実行をブロックします。その理由は、しばしば JavaScript が CSS プロパティの要素への影響を問い合わせるために使われるからです。
CSSOM の構築
クリティカルレンダリングパスの 2 つめのステップは CSS を処理して CSSOM ツリーを構築することです。CSS のオブジェクトモデルは DOM によく似ています。DOM と CSSOM はどちらもツリー構造です。この 2 つは独立したデータ構造を持ちます。ブラウザーは、CSS のルールをブラウザーが理解できるスタイルのマップに変換します。ブラウザーは CSS のルールセットを読み取り、CSS セレクターにもとづいて、親、子、兄弟の関係から構成されるノードのツリーを生成します。
HTML の場合と同様に、ブラウザーは受信した CSS のルールをブラウザーが実行可能な形式に変換しなければいけません。そのために、ブラウザーは HTML をオブジェクトに変換する場合と同じプロセスを CSS に対しても実行します。
CSSOM ツリーはユーザーエージェントのスタイルシートから取得したスタイルを含みます。ブラウザーは、ノードに対して適用される最も一般的なルールからスタートして、より特定されたルールを再帰的に適用し、最終的なスタイルを計算します。つまり、プロパティの値をカスケードします。
CSSOM の構築はとても高速であるため、現在の開発者ツールはそれ自体をユニークな色で表示しません。その代わりに、開発者ツールの「スタイルの再計算」は、CSS を解釈して CSSOM ツリーを構築し、再帰的にスタイルを計算するトータルの時間を表示します。ウェブのパフォーマンスの最適化の観点から言うと、CSSOM を生成するトータルの時間は一般的に1回の DNS 検索にかかる時間よりも少ないため、それほどの苦労はないと言えます。
その他の処理
JavaScript のコンパイル
CSS が解釈され、CSSOM が生成される間、 JavaScript ファイルを含む他のアセットが(事前読み込みスキャナーによって)ダウンロードされます。 JavaScript は構文解析され、コンパイルされ、解釈されます。スクリプトは構文解析によって抽象構文木に変換されます。ブラウザーエンジンによっては、抽象構文木をコンパイラーへ引き渡し、メインスレッドで実行されるバイトコードを出力します。 これは JavaScript コンパイルとして知られています。ほとんどのコードはメインスレッドで動作しますが、ウェブワーカーで実行するコードなど例外もあります。
アクセシビリティツリーの構築
ブラウザーはコンテンツを理解し翻訳する補助機器で使用されるアクセシビリティツリーも構築します。アクセシビリティオブジェクトモデル (AOM) は補助機器向けの DOM のようなものです。ブラウザーは、DOM が更新されるとアクセシビリティツリーも更新します。アクセシビリティツリーは補助機能それ自体からは変更できません。
AOM が構築されるまで、スクリーンリーダー (en-US)でコンテンツにアクセスできません。
レンダリング
レンダリングのステップは、スタイル、レイアウト、描画、そして合成で構成されます。解釈のステップで作成された CSSOM と DOM のツリーはレンダーツリーの形式へと組み合わされ、すべてのビジュアル要素のレイアウトを計算するために使用されて画面に描画されます。いくつかのケースでは、CPU の代わりに GPU を使用して画面の一部を描画し、メインスレッドを解放してパフォーマンスを改善するために、コンテンツ自身をレイヤーに昇格し、合成を行います。
スタイル
クリティカルレンダリングパスの 3 番目のステップは DOM と CSSOM をレンダーツリーの形式へと組み合わせることです。計算されたスタイルのツリー、あるいはレンダーツリー、の構築は DOM ツリーのルートからスタートし、目に見える (Visible) ノードを走査します。
ユーザーエージェントのスタイルシートにある <head> 要素のような表示されることのない要素とその子要素、 display: none を指定されたすべてのノード(script { display: none; } など)は、レンダリングの結果に影響しないためレンダーツリーには含まれません。 visibility: hidden が適用されたノードは、スペースを確保するためレンダーツリーに含まれます。上記のサンプルコード内の script ノードは、ユーザーエージェントの既定値を上書きするディレクティブが指定されていないためレンダーツリーに含まれません。
それぞれの目に見えるノードには、CSSOM のルールが適用されます。レンダーツリーはすべての目に見えるノードをコンテンツと計算されたスタイルを合わせて保持します。すべての関連するスタイルと DOM 上の目に見えるノードをマッチングし、CSS カスケードに基づいて、それぞれのノードに対応する計算されたスタイルを決定します。
レイアウト
クリティカルレンダリングパスの 4 番目のステップは各ノードの平面状の位置を計算するためにレイアウト処理を実行することです。レイアウトはレンダーツリーに含まれるすべてのノードの寸法と位置を決める処理です。さらにページ上のそれぞれオブジェクトの寸法と位置を決定します。再フローは、続いて発生する文書全体、あるいはページの一部分の寸法と位置を決める処理です。
レンダーツリーが構築されるとすぐにレイアウトが始まります。レンダーツリーは計算されたスタイルを踏まえてどのノードが表示されるか (非表示であっても) 特定しますが、寸法や位置は特定しません。各オブジェクトの正確な寸法と位置を決めるために、ブラウザーがレンダーツリーのルートから走査を行います。
ウェブページ上では、ほとんどすべての要素はボックスです。異なるデバイス、異なるデスクトップの設定は、ビューポートの寸法の数が無制限に存在することを示しています。この段階において、ビューポートの寸法を考慮して、ブラウザーはすべての異なるボックスの画面上の寸法を決定します。ビューポートの寸法を基本として、レイアウトは一般的に body からスタートし、すべての body の子孫をそれぞれの要素のボックスモデルプロパティに合わせてレイアウトし、画像のように寸法がわからない代替要素のためのプレースホルダースペースを作成します。
ノードの寸法と位置が決められる最初の瞬間をレイアウトと呼びます。続いて発生するノードの寸法と位置の再計算を再フローと呼びます。私たちの例では、画像が返される前に最初のレイアウトが発生すると考えられます。そこでは画像の寸法を宣言していなかったため、画像の寸法がわかるとすぐに再フローが発生するのです。
描画
クリティカルレンダリングパスの最後のステップは、個別のノードを画面に描画することです。最初に発生する描画を first meaningful paint と呼びます。描画またはラスタライズの段階において、ブラウザーはレイアウト段階で計算されたそれぞれのボックスを画面上の実際のピクセルに変換します。描画は、テキスト、色、境界、シャドウ、ボタンや画像のような置換要素を含む、要素のすべての視覚的な部分を画面に描くことを含みます。ブラウザーはこれを超高速で実行する必要があります。
スムーズなスクロールとアニメーションを実現するために、スタイルの計算や再フロー、描画などメインスレッドを占有するすべての処理は、16.67ms 未満で完了する必要があります。2048 x 1536 の解像度を持つ iPad には 3,145,000 を超えるピクセルがあります。これだけの大量のピクセルを高速に描画しなければいけません。2 回目以降の描画を最初の描画より高速にするため、一般的には画面への描画を複数のレイヤーに分解します。この場合には合成が必要になります。
描画は描画ツリー内の要素をレイヤーに分解します。コンテンツを GPU (CPU 上のメインスレッドの代わりになる) 上のレイヤーに昇格させることで、描画と再描画のパフォーマンスを向上します。<video> や<canvas>など、レイヤーを生成する特定のプロパティと要素があります。opacity、3D transform、will-change、その他いくつかの CSS プロパティを持つ要素も同様です。これらのノードは、その子孫が上記の理由でそれ自身のレイヤーを必要とするのでなければ、子孫と一緒に自身のレイヤー上に描画されます。
レイヤーはパフォーマンスを改善しますが、メモリー管理の面ではコストのかかる処理です。そのため、ウェブのパフォーマンス最適化戦略の中で濫用するべきものではありません。
合成
文書のセクションが異なるレイヤーに描画されていて、それらが重なり合っているとき、コンテンツを画面上に正しい順番で描画するために合成が必要になります。
ページがアセットの読み込みを続ける間も再フローは発生し得ます (上で挙げた、画像が後から取得された例を思い出してください)。再フローは再描画と再合成を引き起こします。もし我々が画像の寸法を指定していた場合、再フローは必要なく、再描画が必要なレイヤーのみが再描画され、必要であれば合成が行われたはずです。しかし、例では画像の寸法を指定していませんでした。つまり画像がサーバーから取得されると、レンダリングプロセスはレイアウトステップまで遡り、そこから再開するのです。
操作可能性
メインスレッドがページの描画を完了したら「これで終わり」と思うかもしれません。しかし、必ずしもそうとは言えません。読み込み処理が、遅延された onload イベントの発行により実行される JavaScript を含む場合、メインスレッドがビジー状態となりスクロールやタッチ、その他の操作ができない場合があります。
Time to Interactive (TTI) は、DNS 検索と TCP 接続を始める最初のリクエストからページが操作可能になるまでどのくらい時間がかかったかを示す測定値です。操作可能であるとは、ページがユーザーの操作に 50ms 以内に応答する First Contentful Paint の後の時点を言います。メインスレッドが構文解析、コンパイル、JavaScript の実行に占有されている場合、ユーザーの操作にタイムリーに (50ms より早く) 応答することができません。
以下の例では、画像の読み込みは高速かもしれませんが、anotherscript.js ファイルが 2MB あり、しかもユーザーのネットワークは低速です。このケースでは、ユーザーはページのコンテンツをすぐに見ることができるかもしれませんが、スクリプトがダウンロードされるまでスクロールを実行できない可能性があります。これは良いユーザー体験とは言えません。この WebPageTest の例からわかるように、メインスレッドを占有することは避けなければいけません。
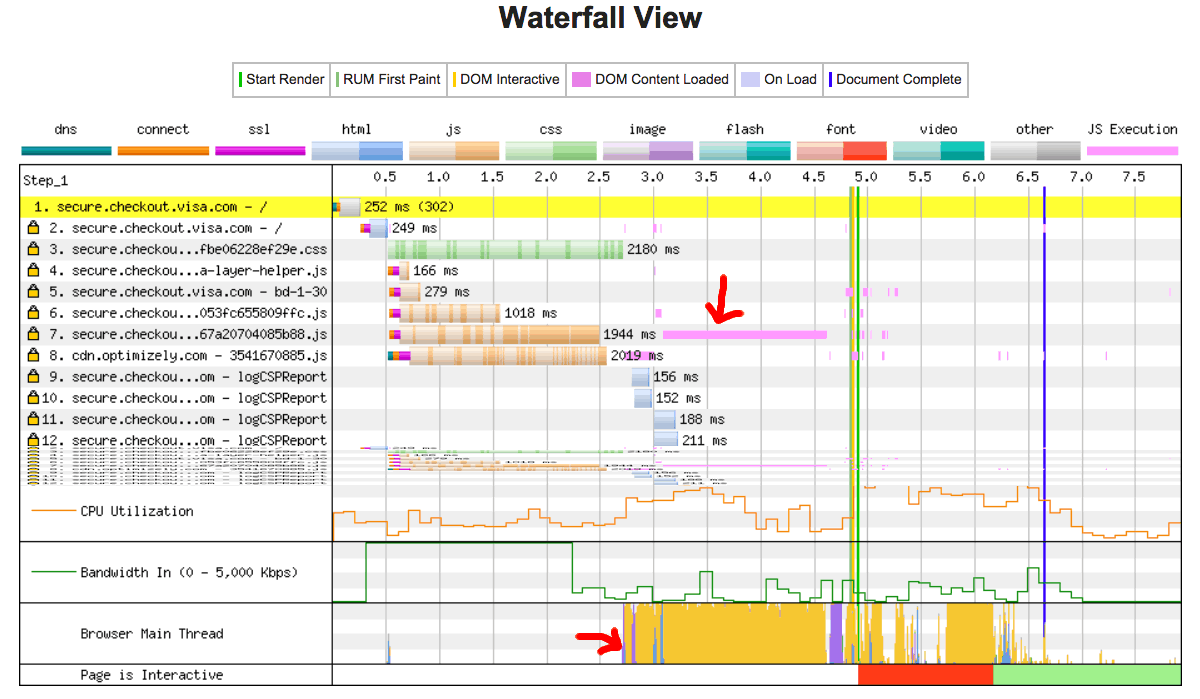
この例では、 JavaScript の実行には 1.5 秒以上かかっており、メインスレッドがすべての時間を完全に占有され、クリックイベントや画面のタップに応答できなくなっています。