Django Tutorial Part 6: Generic list and detail views
이 튜토리얼은 LocalLibrary website에 책과 저자의 목록과 세부 페이지를 추가 하여 확장할 것입니다. 이 글에서 우리는 제네릭 클래스-기반 뷰(generic class-based views)에 대해 배울 것이며, 그것이 일반적인 사용 사례를 위해 작성해야 하는 코드들을 줄이는 방법을 보여줄 것입니다. 우리는 또한 URL 처리에 대해 더 세부적으로 알아볼 것이며, 기본 패턴 매칭(basic pattern matching)을 수행하는 방법을 보여줄 것입니다.
| 사전 준비: | Django Tutorial Part 5: Creating our home page를 포함한 모든 이전 튜토리얼을 완료하세요. |
|---|---|
| 목표: | 제네릭 클래스-기반 뷰를 어디 그리고 어떻게 사용하는지, 그리고 어떻게 URL들로부터 패턴들을 추출하여 정보를 view들에게 전달하는지에 대해 이해하기. |
개요
이 튜토리얼에서 우리는 책과 저자에 대한 목록과 세부 페이지(detail page)를 추가하여 LocalLibrary 웹사이트의 첫 번째 버전을 완성할 것입니다(더 정확하게는, 우리는 책 페이지들을 구현하는 방법을 보여주고, 저자 페이지는 스스로 완성하도록 할 것입니다!)
이 과정은 이전 튜토리얼에서 보여준, 색인 페이지(index page)를 만드는 과정과 비슷합니다. 우리는 여전히 URL 맵들, view들, 그리고 탬플릿들을 만들어야 합니다. 주요한 차이점은 세부 페이지(detail pages)에서, 우리는 URL 안의 패턴에서 정보를 추출해서 view로 전달하는 추가적인 도전을 가진다는 점입니다.
이 튜토리얼의 마지막에서는 제네릭 클래스-기반 뷰를 사용할 때 데이터의 페이지를 매기는 방법을 보여드리겠습니다.
책 목록 페이지
책 목록 페이지는 모든 사용 가능한 책 레코드들의 목록을 페이지 안에 나타낼 것이며, 다음 URL을 사용하여 접근합니다: catalog/books/. 이 페이지는 각 레코드마다 제목과 저자를 나타낼 것이며, 제목은 관련된 책 페이지로 이동하는 하이퍼링크 처리됩니다. 이 페이지는 사이트의 다른 페이지들과 같은 구조와 내비게이션을 가지고 있어서, 우리는 이전 튜토리얼에서 만들었던 템플릿(base_generic.html)을 확장해서 사용하면 됩니다.
URL mapping
/catalog/urls.py 파일을 열고 아래 코드박스의 굵은 글씨를 복사해 붙여넣으세요. 인덱스 페이지처럼 path() 함수는 URL('books/')과 매치되는 패턴, URL이 매치될 때 호출되는 view 함수(views.BookListView.as_view()), 그리고 이 특정 매핑에 대한 이름을 정의합니다.
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
]
이전 튜토리얼에서 URL은 이미 /catalog 와 매치되었을 것입니다. 그래서 사실상 view는 /catalog/books/ URL에 접속하면 호출됩니다.
View함수는 이전과 다른 형태를 가집니다. 왜냐면 이 view는 사실 클래스로 구현이 되기 때문입니다. 우리는 이 view를 직접 구현하지 않고, 이미 존재하는 generic view 함수를 상속받아 view 함수를 구현할 것입니다. 이 generic view 함수는 우리가 구현하고 싶은 기능들을 거의 다 가지고 있습니다.
Django의 클래스 기반 view에서는, as_view()클래스 메소드를 호출해 적절한 view 함수에 접근할 수 있습니다. 이건 클래스의 인스턴스를 생성하는 작업과 모든 HTTP 요청을 처리하는 핸들러 메소드가 제대로 동작하는지를 처리합니다.
뷰(클래스 기반)
표준 function으로 우리는 꽤나 쉽게 book list view를 만들 수 있는데 (마치 이전 우리의 index view같이), 모든 책에 대한 데이터 베이스 쿼리를 만들어서 render() 함수를 불러 특정 템플릿에 리스트를 보냅니다. 대신 우리는 class-based generic list view (ListView) 를 사용하는데— 존재하는 뷰로부터 상속받아온 클래스입니다. generic view가 이미 우리가 필요한 대부분의 기능성을 실행하면서 동시에 Django best-practice이기 때문에, 우리는 코드의 양과 반복을 줄이고 궁극적으로 유지보수에 수고가 덜 드는 견고한 리스트 뷰를 만들 수 있습니다.
catalog/views.py 파일을 열고, 아래의 코드를 views.py 파일 가장 아래에 붙여넣기하세요.
from django.views import generic
class BookListView(generic.ListView):
model = Book
이게 전부입니다! Generic view는 명시된 모델(Book)의 모든 레코드를 가져오기 위해 데이터베이스를 쿼리할 것이고, /locallibrary/catalog/templates/catalog/book_list.html(아래에서 만들 예정)경로에 있는 템플릿을 렌더링합니다. 템플릿 안에서 우리는 object_list나 book_list라는 템플릿 변수를 사용해 도서 목록에 접근할 수 있습니다. (일반적으로 "the_model_name_list").
참고: 이 어색한 템플릿 경로는 오타가 아닙니다. Generic views는 /application_name/the_model_name_list.html(지금 상황에서는 catalog/book_list.html)에서 템플릿을 찾습니다. 이 경로는 애플리캐이션의 /application_name/templates/ 디렉토리 안에 있습니다(/catalog/templates/).
속성이나 디폴트 동작을 추가할 수도 있습니다. 예를 들어, 같은 모델을 사용하지만 여러 개의 뷰를 사용해야 되는 경우 다른 템플릿 파일을 명시할 수 있습니다. 혹은 book_list 템플릿 변수명이 직관적이지 않다고 생각해 다른 템플릿 변수명을 사용하고 싶을지도 모릅니다. 아마 가장 유용한 바리에이션은 리턴 값의 결과를 바꾸거나 필터링하는 것입니다. 따라서 모든 책을 나열하는 대신, 유저가 읽은 순으로 5개의 책을 나열할 수도 있습니다.
class BookListView(generic.ListView):
model = Book
context_object_name = 'my_book_list' # your own name for the list as a template variable
queryset = Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
template_name = 'books/my_arbitrary_template_name_list.html' # Specify your own template name/location
클래스 기반 뷰의 메소드 오버라이딩
굳이 여기서 할 필요는 없지만, 클래스 메소드 오버라이딩을 할 수도 있습니다.
예를 들어, 우리는 get_queryset()메소드를 오버라이딩해 반환되는 레코드의 리스트들을 바꿀 수 있습니다. 이건 우리가 이전에 했던 queryset 속성을 지정하는 방법보다 더 유연한 방법입니다. (비록 지금 상황에서 별 이득이 되지는 않지만요.)
class BookListView(generic.ListView):
model = Book
def get_queryset(self):
return Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
우리는 템플릿에 추가적인 컨텍스트 변수들을 전달하기 위해 get_context_data()를 오버라이딩할 수도 있습니다. (도서 목록이 디폴트로 전달됩니다.) 아래의 코드는 some_data 라는 이름의 변수를 어떻게 컨텍스트에 추가하는지를 보여줍니다. (이렇게 하면 템플릿 변수로 사용할 수 있습니다.)
class BookListView(generic.ListView):
model = Book
def get_context_data(self, **kwargs):
# Call the base implementation first to get the context
context = super(BookListView, self).get_context_data(**kwargs)
# Create any data and add it to the context
context['some_data'] = 'This is just some data'
return context
이렇게 할 때에는, 아래의 패턴을 따르는 것이 중요합니다:
- 첫째로, 슈퍼클래스에서 기존 컨텍스트를 가져옵니다.
- 그리고 새로운 컨텍스트 정보를 추가합니다.
- 마지막으로 새롭게 업데이트된 컨텍스트를 리턴합니다.
참고: Built-in class-based generic views (Django docs)를 방문해 다양한 예제를 살펴볼 수 있습니다.
리스트 뷰 템플릿 생성하기
/locallibrary/catalog/templates/catalog/book_list.html 경로에 HTML 파일을 만든 다음, 아래의 코드를 복사, 붙여넣기 하세요. 이전에 설명한 것처럼, 이건 제네릭 클래스 기반 리스트 뷰에서 예상되는 기본 템플릿 파일입니다. (catalog 애플리케이션 내의 Book 모델)
제네릭 뷰의 템플릿은 다른 템플릿과 비슷합니다 (물론 템플릿에 전달되는 컨텍스트나 정보는 다를지도 모르지만요). 다른 index 템플릿처럼, 우리는 첫번째 줄에 base 템플릿을 넣어 확장한 다음, content라는 이름의 블록으로 교체합니다.
{% extends "base_generic.html" %}
{% block content %}
<h1>Book List</h1>
{% if book_list %}
<ul>
{% for book in book_list %}
<li>
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
</li>
{% endfor %}
</ul>
{% else %}
<p>There are no books in the library.</p>
{% endif %}
{% endblock %}
뷰는 object_list나 book_list라는 디폴트 aliases로 컨텍스트(도서 목록)를 전달합니다. object_list나 book_list 둘 중 어느 것을 적어도 상관이 없습니다.
조건부 실행
if, else 그리고 endif 라는 템플릿 태그들은 book_list 이 정의되었는지, 그리고 존재하는지 체크합니다. 만약 book_list가 없다면, 책이 존재하지 않는다는 else 절의 텍스트 문구가 표시될 것입니다. 만약 book_list가 존재한다면, 도서 목록의 갯수만큼 반복만큼 반복해서 실행합니다.
{% if book_list %}
<!-- code here to list the books -->
{% else %}
<p>There are no books in the library.</p>
{% endif %}
위의 조건문은 단 하나의 상황만 체크합니다. 하지만 elif라는 템플릿 태그를 사용해 추가적인 조건을 걸어 테스트할 수 있습니다. (예를 들면 {% elif var2 %}) 조건부 연산자에 대한 자세한 내용은 다음 링크에서 확인할 수 있습니다: if, ifequal/ifnotequal, and ifchanged in Built-in template tags and filters (Django Docs).
반복 구문
for 와 endfor 라는 템플릿 태그들은 아래와 같이 도서 목록을 살펴보는 루프를 위해 사용합니다. 각각의 반복은 book 템플릿 변수에 현재 리스트 아이템에 대한 정보를 채웁니다.
{% for book in book_list %}
<li><!-- code here get information from each book item --></li>
{% endfor %}
여기에서는 사용되지 않지만, 반복 구문 내에서 Django는 반복을 추적할 수 있는 다른 변수들을 만들 수 있습니다. 예를 들어, forloop.last라는 변수로 루프의 마지막 실행에 대한 조건부 처리을 할 수 있습니다.
변수 접근하기
반복 구문 내에서의 코드는 각각의 책에 대한 리스트 아이템을 생성합니다. 이 리스트 아이템은 타이틀(아직 작성되지 않은 상세 뷰의 링크)과 작가의 이름을 나타냅니다.
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
우리는 점 표기법(dot notation)을 사용해서 연관된 책의 레코드(예를 들어 book.title 과 book.author)에 대한 필드에 접근이 가능합니다. book 다음의 텍스트는 모델에 정의되어있는 필드의 이름입니다.
우리는 템플릿 안에 모델에서 정의한 함수를 불러올 수도 있습니다. 이 경우, 우리는 Book.get_absolute_url() 함수를 호출해 연관된 세부 레코드를 표시하는 URL을 가져옵니다. 이 작업은 함수가 아무 인자를 가지지 않을 때 제공됩니다 (여기에는 인자를 넘길 방법이 없습니다!).
참고: 우리는 템플릿 내에서 함수를 호출할 때 발생하는 부작용을 조금 조심해야 합니다. 여기서 우리는 그저 표시하기 위해 URL을 얻었지만, 함수는 그보다 더한 작업도 할 수 있습니다 — (예를 들면) 우리는 그냥 템플릿을 렌더링한다고 해서 우리의 데이터베이스를 삭제하고 싶지 않을 것입니다.
베이스 템플릿 업데이트
베이스 템플릿(/locallibrary/catalog/templates/base_generic.html)을 열고 All books의 URL 링크 부분에 {% url 'books' %} 코드를 삽입하세요. 이건 모든 페이지 링크에 적용될 것입니다 (우리는 "books" url mapper를 만들었으니 이렇게 넣을 수 있습니다.)
<li><a href="{% url 'index' %}">Home</a></li>
<li><a href="{% url 'books' %}">All books</a></li>
<li><a href="">All authors</a></li>
어떻게 보일까요?
우리는 아직 도서 목록을 표시할 수 없습니다. 왜냐면 디펜던시(dependency)가 없기 떄문이죠. 책의 상세 페이지에 대한 URL이 필요한데, 이 URL은 각 도서에 대한 하이퍼 링크입니다. 다음 섹션 이후에는 목록보기와 상세보기가 모두 표시될 것입니다.
Book 상세 페이지
URL catalog/book/<id> ( <id> 는 book의 primary key입니다)에 접근해서, Book의 상세 페이지는 특정 책의 정보를 보여줄 것입니다. Book 모델 (author, summary, ISBN, language, 그리고 genre) 같은 필드에 추가로, 우리는 가능한 복사본(BookInstances) 의 상세부분, 즉 상태와 기대하는 반납일, 기록 그리고 아이디 등을 리스트화 할 것입니다. 이렇게 하면 독자들이 책의 리스트를 확인할 뿐만 아니라, 언제 책을 대여할 수 있는지에 대한 여부를 확인할 수 있게 해줍니다.
URL 매핑
/catalog/urls.py 파일을 열고 아래 두꺼운 글씨로 된 book-detail URL mapper를 추가하세요. path() 함수는 연관된 제네릭 클래스 기반의 상세 뷰와 이름에 대한 패턴을 정의합니다.
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
path('book/<uuid:pk>', views.BookDetailView.as_view(), name='book-detail'),
]
book-detail URL 패턴은 우리가 원하는 책의 id를 캡처하기 위해 특별한 구문을 사용합니다. 구문은 간단합니다: 꺾쇠 괄호는 캡처하는 URL의 일부를 정의하고 뷰가 캡처 된 데이터에 액세스하는 데 사용할 수있는 변수의 이름을 지정합니다. 예를 들어, <something> 은 패턴을 캡처해서 "something"이라는 변수에 데이터를 담아 전달합니다. 우리는 선택적으로 변수 이름 앞에 데이터 형식 (int, str, slug, uuid, path)을 정의하는 converter specification을 사용할 수 있습니다.
여기에서 우리는 book id을 캡쳐하기 위해 '<uuid:pk>' 라는 특별히 포맷화된 문자열을 활용할 것입니다. 그리고 pk (primary key의 단축어)라는 이름의 파라미터로서 뷰로 넘겨줄 것입니다. This is the id that is being used to store the book uniquely in the database, as defined in the Book Model.
(번역 봉사자 주: uuid를 읽지 못한다면[NoReverseMatch] <int:pk>로 해보십시오.)
참고: 앞에서 언급했듯이, 관련된 URL 은 실제로는 catalog/book/<digits> 입니다.(우리가 catalog application 에 있기때문에, /catalog/ 를 가정합니다).
경고: 명심: 통상 class-based detail view 는 pk 라는 이름을 가진 파라미터로 전달됩니다. 만일 자체적으로 function view 를 만든다면 어떤 이름이라도 사용 가능합니다. 혹은 이름이 없는 argument 에 정보를 넣어 전달 할 수도 있습니다.
Regular expression 을 이용한 고급 path matching
참고: 튜터리얼과는 관련 없습니다. 하지만 향후 Django 스타일로 개발하기 위해선 매우 유용한 팁입니다.
path() 를 이용한 패턴 검색은 간단하고 일반적인 경우 - 예를 들어 단지 특정 문자열이나 숫자가 있는지 - 매우 유용합니다. 만일 좀더 세밀한 조건 - 예를 들어 특정 문자열 길이를 갖는 문자열 검색 - 으로 검색 하고자 한다면 . re_path() 를 사용하길 권고 드립니다.
re_path() 는 Regular expression 을 사용한다는 점만 빼고 path() 와 똑 같습니다. 예를 들어 앞서 서술한 path 는 다음과 같이 re_path 로 대체 사용 가능합니다.
re_path(r'^book/(?P<pk>\d+)$', views.BookDetailView.as_view(), name='book-detail'),
Regular expressions 은 정말로 파워풀한 매핑 툴 입니다. 하지만 솔직히 직관적이지 못하고 초보자에게는 두려운 존재입니다. 아래는 간단한 지침서 입니다!
첫번째로 regular expressions 은 the raw string literal syntax 로 선언되어야 합니다 (즉, 다음처럼 '< >' 로 닫혀 있어야 한다는 겁니다: r'<your regular expression text goes here>').
패턴 매칭을 정의하기 위해 알아야 될 문법의 핵심적인 부분들입니다:
| Symbol | Meaning |
|---|---|
| ^ | 기술된 text 로 그 문자열이 시작되는지 |
| $ | 기술된 text 로 그 문자열이 끝나는지 |
| \d | 숫자(0, 1, 2, ... 9) 인지 |
| \w | word character 인지. 즉, 대소문자, 숫자, underscore character (_) 로만 구성된 단어인지. |
| + | 하나 이상의 선행 문자가 있는지. 예를 들어, 하나 이상의 숫자와 매치한다면 \d+.를 하나 이상의 'a' 문자와 매치 한다면 a+ |
| * | 매치되는 문자열이 없거나 많은 경우, 예를 들어 매칭이 안되거나 한 단어를 찾고자 할 경우 \w* |
| ( ) | 괄호안에 있는 패턴의 일부를 선택할때. 선택된 값은 unnamed parameter 로 view 에게 전달된다. (만일 여러 패턴들이 선택 되었다면 선택된 순서대로 연관된 파라미터로써 전달 될것입니다. |
| (?P<name>...) | (...에 표기된) 패턴을 명명한 variable로 변환합니다(이 경우에는 "name" 입니다). 변환한 이름을 view 에 지정한 이름으로 넘깁니다. 그러므로 당신의 view 에서는 반드시 argument명을 동일하게 해주어야 합니다! |
| [ ] | 집합 set 안에 있는 글자중 한개와 매치 될때. 예를 들어 [abc] 는 'a',혹은 'b' 혹은 'c' 와 매치되는지. [-\w] 는 '-' 한 글자 인지 혹은 '-'를 포함한 단어와 매치 하는지를 나타냅니다. |
대부분의 다른 글자들은 문자 그대로 받아 들여 집니다!
몇 가지 실제 패턴 예제를 보도록 합시다:
| Pattern | Description |
|---|---|
| r'^book/(?P<pk>\d+)$' | 이것은 우리가 URL mapper에서 사용한 Regular Expression입니다. 이 표현식은 먼저 문자열이 book/ 으로 시작하는지 검사하고 (^book/), 그 다음에 한 개이상의 숫자가 오는지 (\d+), 그리고 문자열이 끝나기 전에 숫자가 아닌 문자가 들어 있지는 않는 지 검사합니다.또한 이 표현식은 모든 숫자들을 변환하고 (?P<pk>\d+) 변환된 값을 view 에 'pk'라는 이름의 parameter로 넘깁니다. 변환된 값은 항상 String type으로 넘어갑니다!예를 들어, 이 표현식은 book/1234 을 매칭합니다. 그리고 변수 pk='1234' 를 view에 넘깁니다. |
| r'^book/(\d+)$' | 이 표현식은 위의 표현식과 동일한 URL들을 매칭합니다. 변환된 정보는 명명되지 않은 argument로 view에 전달됩니다. |
| r'^book/(?P<stub>[-\w]+)$' | 이 표현식은 문자열 처음 부분에 book/ 으로 시작하는지 검사하고 (^book/), 그리고 한 개 또는 그 이상의 '-' 나 word character가 오고 ([-\w]+), 그렇게 끝내는지를 매칭합니다. 이 표현식 또한 매칭된 부분을 변환하고 view 에 'stub' 라는 이름의 parameter로 전달합니다.This is a fairly typical pattern for a "stub". Stubs are URL-friendly word-based primary keys for data. You might use a stub if you wanted your book URL to be more informative. For example /catalog/book/the-secret-garden rather than /catalog/book/33. |
당신은 다양한 패턴들을 한번의 매칭을 통해 변환시킬 수 있습니다. 그러므로 다양한 정보들을 URL안에 인코딩할 수 있습니다.
참고: 추가적으로, 특정 날짜에 출간된 책 목록을 URL에 인코딩할 수 있을지 생각해보세요. 그리고 어떤 Regular Expression이 해당 URL을 매칭할 수 있을까요?
Passing additional options in your URL maps
우리가 여태까지 사용하지는 않았지만, 쓸모있을만한 한 기능은 당신이 additional options 을 정의내리고 view에 전달할 수 있다는 것입니다. 이 option들은 dictionary 형태로 정의하고 path() 함수의 3번째 명명되지 않은 argument로 전달됩니다. 이 방식은 만약, 당신이 동일한 view 를 다른 곳에서 재활용하려고 하거나, 각 상황에 맞게 조절하려고 할 때 유용합니다. (이 경우, 우리는 각 경우에 따라 다른 template 을 제공합니다).
path('url/', views.my_reused_view, {'my_template_name': 'some_path'}, name='aurl'),
path('anotherurl/', views.my_reused_view, {'my_template_name': 'another_path'}, name='anotherurl'),
참고: 추가된 options 과 변환된 패턴들 중 명명된 것들은 view 에 명명된 arguments로 전달됩니다. 만약 당신이 동일한 이름을 변환된 패턴들과 추가적인 option에 사용한다면, 오직 변환된 패턴들만이 view에 보내지게 됩니다. ( 추가된 option들에 있는 값들은 모두 버려집니다).
뷰 (클래스 기반)
catalog/views.py 을 열고, 다음 코드를 파일 끝에 넣으세요:
class BookDetailView(generic.DetailView):
model = Book
다됬습니다! 이제 해야될 일은 /locallibrary/catalog/templates/catalog/book_detail.html template를 만들면, view는 template에 URL mapper에 의해 찾고자 하는 데이터베이스에 있는 특정 Book 레코드의 정보를 전달할 겁니다. template 안에서 template 변수 object 또는 book(즉, 일반적으로는 "해당_모델_명") 으로 책 목록에 접근할 수 있습니다.
만약 필요하다면, 사용하고 있는 template 또는 template 안에서 book을 참조하는 데 사용되는 context object의 이름을 바꿀 수 있습니다. 또한, 예를 들어 context에 정보를 추가하는 식으로, 메서드를 오버라이드 할 수도 있습니다.
만약 해당 레코드가 존재하지 않는다면 무슨 일이 일어날까요?
만약 요청된 레코드가존재하지 않는다면, 제네릭 클래스 기반의 detail view는 Http404 exception 이 저절로 발생할 것입니다. — 만들어질 때, 적절한 "resource not found" 페이지를 알아서 보여줄 것입니다. 만약 원한다면 당신이 해당 페이지를 수정할 수 있겠죠.
이런 일이 어떻게 발생하는지 원리를 조금 알려줄게요. 밑에 있는 코드는 만약 당신이 제네릭 클래스 기반의 detail view를 사용하지 않는다면, 클래스 기반의 view를 어떻게 함수 형태로 표현 할 수 있는지 보여줍니다.
def book_detail_view(request, primary_key):
try:
book = Book.objects.get(pk=primary_key)
except Book.DoesNotExist:
raise Http404('Book does not exist')
return render(request, 'catalog/book_detail.html', context={'book': book})
view는 먼저 model로 부터 특정 book 의 레코드를 얻으려고 할 것입니다. 이 시도가 실패하면, view 는 "해당 책이 존재하지 않음"을 알려주면서 Http404 exception가 발생할 것입니다. 그리고 마지막 과정은 ,평소처럼, book 정보를 context parameter (dictionary 형태로)에 집어 넣고 template 이름과 함께 render() 함수를 호출 할 것입니다.
혹, 만약 해당 레코드를 찾지 못한다면, 우리는 손쉬운 방법으로 Http404 exception을 발생하기 위해get_object_or_404() 함수를 사용할 수도 있어요.
from django.shortcuts import get_object_or_404
def book_detail_view(request, primary_key):
book = get_object_or_404(Book, pk=primary_key)
return render(request, 'catalog/book_detail.html', context={'book': book})
상세 뷰 템플릿 생성하기
/locallibrary/catalog/templates/catalog/book_detail.html 파일을 만들고, 아래 텍스트를 복사 붙여넣기 하세요. 위에서 설명한대로, 이 파알명은 제네릭 클래스 기반 상세 뷰의 디폴트 파일명입니다. (catalog 애플리케이션의 Book 모델을 위한 상세 뷰)
{% extends "base_generic.html" %}
{% block content %}
<h1>Title: {{ book.title }}</h1>
<p><strong>Author:</strong> <a href="">{{ book.author }}</a></p> <!-- author detail link not yet defined -->
<p><strong>Summary:</strong> {{ book.summary }}</p>
<p><strong>ISBN:</strong> {{ book.isbn }}</p>
<p><strong>Language:</strong> {{ book.language }}</p>
<p><strong>Genre:</strong> {% for genre in book.genre.all %} {{ genre }}{% if not forloop.last %}, {% endif %}{% endfor %}</p>
<div style="margin-left:20px;margin-top:20px">
<h4>Copies</h4>
{% for copy in book.bookinstance_set.all %}
<hr>
<p class="{% if copy.status == 'a' %}text-success{% elif copy.status == 'm' %}text-danger{% else %}text-warning{% endif %}">{{ copy.get_status_display }}</p>
{% if copy.status != 'a' %}
<p><strong>Due to be returned:</strong> {{copy.due_back}}</p>
{% endif %}
<p><strong>Imprint:</strong> {{copy.imprint}}</p>
<p class="text-muted"><strong>Id:</strong> {{copy.id}}</p>
{% endfor %}
</div>
{% endblock %}
참고: 이 템플릿의 작가 링크는 비어있는 URL입니다. 왜냐면 우리는 아직 작가 상세 페이지를 만들지 않았기 때문이죠. 만약 페이지가 존재한다면, URL을 아래와 같이 업데이트 해야합니다.
<a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a>
조금 더 커졌지만, 이 템플릿의 대부분의 것들은 이미 언급된 것들입니다:
- content 블럭을 오버라이드 해서 우리의 기본 템플릿을 extend하였습니다.
- 우리는 조건 판단 처리를 해서 특정 컨텐츠가 있을지 없는지 체크하여 표시합니다.
for루프를 활용하여 objects들의 리스트를 표현합니다.- 우리는 context fields를 dot notation를 활용합니다 (왜냐하면 우리는 detail generic view를 사용하는데, context의 이름은
book이기에 우리는 "object"를 사용할 수 있습니다)
우리가 본 적 없는 한가지 흥미로운 점은 바로 book.bookinstance_set.all() 함수입니다. 이 메소드는 Django에 의해 자동으로 만들어진 메소드입니다. 이 메소드는 Book 과 관련된 BookInstance 레코드 집합을 반환합니다.
{% for copy in book.bookinstance_set.all %}
<!-- code to iterate across each copy/instance of a book -->
{% endfor %}
이 메소드는 관계의 한쪽("one")에만 ForeignKey(one-to many) 필드를 선언했기 때문에 필요합니다. 다른("many") 모델에서 아무것도 선언하지 않았기 때문에 관련 레코드 집합을 가져올 필드가 없습니다. 이 문제를 해결하기 위해, Django는 지금 우리가 사용하고 있는 "reverse lookup"이라는 적당한 이름의 함수를 만들었습니다. 이 함수의 이름은 ForeignKey가 선언되어있는 모델 이름을 소문자로 만들고, 그 뒤에 _set을 붙이면 됩니다. (따라서 Book에서 만든 함수는 bookinstance_set()가 되겠죠.)
참고: 여기서 우리는 모든 레코드를 가져오기 위해 all() 을 사용했습니다(기본값이죠). 반대로 당신은 filter() 메서드를 사용해서 레코드의 부분 집합을 가져올 수 있지만, 당신은 template에서 이걸 직접할 수는 없어요. 왜냐하면 함수의 arguments를 정할 수 없으니까요.
만약 순서를 정의하지 않는다면 (클래스 기반 view 또는 model에서), 당신은 개발 서버로 부터 다음과 같은 에러를 받게 될 거라는 것 또한 알아두세요.
[29/May/2017 18:37:53] "GET /catalog/books/?page=1 HTTP/1.1" 200 1637 /foo/local_library/venv/lib/python3.5/site-packages/django/views/generic/list.py:99: UnorderedObjectListWarning: Pagination may yield inconsistent results with an unordered object_list: <QuerySet [<Author: Ortiz, David>, <Author: H. McRaven, William>, <Author: Leigh, Melinda>]> allow_empty_first_page=allow_empty_first_page, **kwargs)
이것은 paginator object 가 데이터베이스에서 ORDER BY 명령어가 실행되었을 것이라고 예상하기 때문에 발생하는 것입니다. 이러한 것이 없다면, 레코드들이 정확한 순서로 반환되었는지 알 수가 없어요!
이 튜토리얼은 아직 Pagination 에 도달하지는 않았습니다.(곧 하게될 거에요) sort_by() 에 parameter를 전달하여 사용하는 것은 (위에서 이야기했던 filter() 와 동일한 역할을 합니다.) 사용할 수 없기 때문에, 당신은 3개의 선택권중에 하나를 골라야합니다:
- Add a
orderinginside aclass Metadeclaration on your model. - Add a
querysetattribute in your custom class-based view, specifying aorder_by(). - Adding a
get_querysetmethod to your custom class-based view and also specify theorder_by().
만약 Author model에 class Meta 사용하기를 결정했다면 (커스터마이징 된 클래스 기반 view만큼 유연하진 않겠지만, 쉬운 방법입니다), 아마 밑에 코드와 비슷하게 끝날 거에요:
class Author(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
date_of_birth = models.DateField(null=True, blank=True)
date_of_death = models.DateField('Died', null=True, blank=True)
def get_absolute_url(self):
return reverse('author-detail', args=[str(self.id)])
def __str__(self):
return f'{self.last_name}, {self.first_name}'
class Meta:
ordering = ['last_name']
물론, 해당 field는 last_name 이어야 할 필요는 없습니다: 다른 어떤 것도 될 수 있어요.
마지막으로, 그러나 적어도 우리는 정렬(sort)을 attribute/column에 따라 해줘야 합니다. unique 여부와 상관없이 당신의 database의 퍼포먼스 이슈를 위해서 필요합니다. 물론, 이것은 여기서 필요한 것이 아니며 어떻게 보면 약간 진도를 앞서나가는 것 같지만 이런 작은 사용자와 프로젝트에서도 미래의 프로젝트를 위해서 미리 명심해 두는 것이 좋습니다.
어떻게 보일까요?
이 시점에서 책 목록 페이지와 책 세부 사항 페이지를 보기 위한 모든 것을 만들어 놓았어야 합니다. 명령어 (python3 manage.py runserver) 를 입력하여 서버를 실행하고 브라우저를 열어 http://127.0.0.1:8000/ 에 접속해보세요.
경고: 주의!: 아직 작가 목록 페이지나 작가 세부 사항 페이지를 클릭하시면 안됩니다. — 당신은 challenge에서 이것들을 만들어보게 될 거에요!
책 목록을 보기 위해 All books 링크를 클릭하세요.
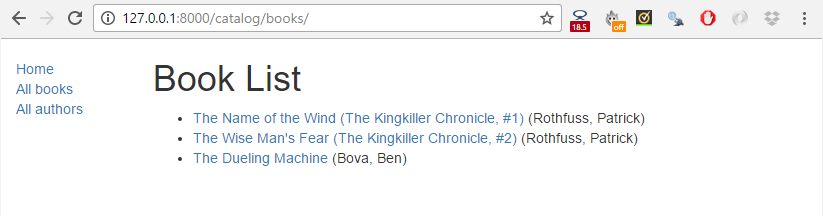
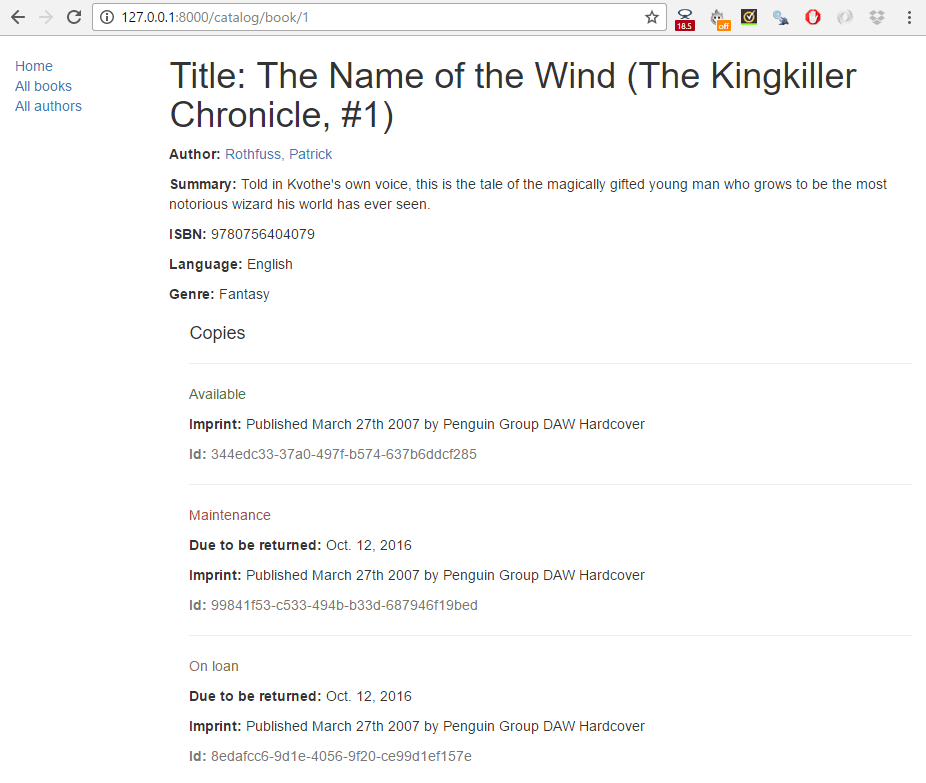
그리고 당신의 책들 중 하나를 클릭해보세요. 만약, 현재까지의 과정을 성공적으로 따라왔다면, 당신은 다음과 같은 스크린샷을 볼 수 있을 겁니다.
Pagination
만약 레코드가 몇 개 없다면, 현재의 책 목록 페이지도 괜찮습니다. 하지만 수십,수백개의 레코드를 갖고 있다면, 페이지는 가져오는 데 점차 시간이 늘어날 겁니다(양이 너무 많아 탐색하는게 체감적으로 힘들어질 정도로요). 해결 방법은 당신의 list view에 pagination을 추가하는 것입니다, 그리고 pagination은 각 페이지마다 보여주는 항목들을 감소시켜줄 것입니다.
장고는 pagination에 대한 훌륭한 지원을 하고 있습니다. 더욱 좋은 점은,이 지원은 제네릭 클래스 기반 list view에 내장되어 있어서, 당신이 pagination을 하기 위해 해야될 것이 많지 않다는 것입니다!
Views
catalog/views.py열고, 밑에 굵은 글씨로 작성되어있는 paginate_by 줄을 추가해주세요.
class BookListView(generic.ListView):
model = Book
paginate_by = 10
이 것이 추가됨에 따라, 당신이 10개 이상의 레코드를 갖게 되면 view는 template에 보내는 데이터에 pagination 하는 것을 시작할 것입니다. 다른 page들을 GET parameter들을 통해 접근할 수 있습니다— 2 페이지에 접속하려면, 다음과 같은 URL을 사용하세요: /catalog/books/?page=2.
Templates
자료들이 pagination되었습니다, 우리는 template에 결과들을 훑어볼 수 있도록 만들어야합니다. 우리는 이러한 기능이 모든 list view들에 필요할 수 있으므로, 우리는 base template에 추가하는 방향으로 작업을 진행하려고 합니다.
/locallibrary/catalog/templates/base_generic.html 열고 content block 밑에 다음과 같은 pagination block을 복사하여 추가하세요 (아래에 굵은 글씨로 강조표시를 해놓았습니다). 첫번째로 코드는 현재 페이지가 pagination이 가능한지 체크합니다. 만약 가능하다면, 다음 페이지와 전 페이지를 적절히 추가합니다 (현재 페이지 넘버도요).
{% block content %}{% endblock %}
{% block pagination %}
{% if is_paginated %}
<div class="pagination">
<span class="page-links">
{% if page_obj.has_previous %}
<a href="{{ request.path }}?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="page-current">
<p>Page {{ page_obj.number }} of {{ page_obj.paginator.num_pages }}.</p>
</span>
{% if page_obj.has_next %}
<a href="{{ request.path }}?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endif %}
{% endblock %}
만약 현재 페이지에 pagination이 사용중이라면, page_obj 가 Paginator 오브젝트 로서 존재합니다. 해당 오브젝트는 현재 페이지, 전 페이지, 페이지 수는 얼마나 되는 지등의 모든 정보를 제공합니다.
pagination 링크를 만들기 위해 우리는 {{ request.path }} 를 이용하여 현재 페이지의 URL을 가져오도록 할 겁니다. 우리가 pagination을 하는 객체와 독립적이기 때문에 유용합니다.
다됬네요!
어떻게 보일 까요?
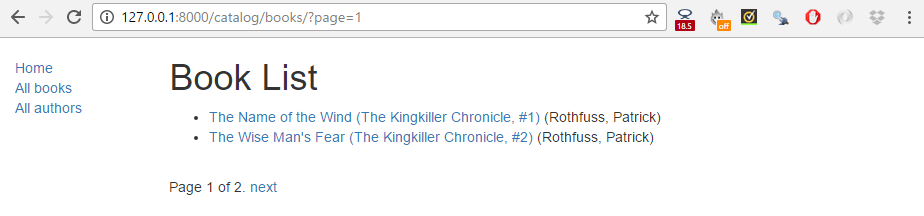
밑에 있는 스크린샷은 pagination이 어떻게 보이는지를 알려줍니다 — 만약 데이터베이스에 10개가 넘는 제목을 추가하지 않았다면, catalog/views.py 파일에 있는 paginate_by 줄에 있는 숫자를 낮춤으로써 쉽게 테스트할 수 있습니다. 밑에 있는 결과는 우리가 paginate_by = 2로 바꾼 겨로가입니다.
next/previous 링크와 함께 보이는 밑에 pagination 링크는 당신이 어느 페이지에 있느냐에 따라 달리 표시가 됩니다.
도전과제
이번 글의 과제는 프로젝트를 완수하기 위해 필요한 작가 세부 사항과 목록 view들을 만드는 것입니다. 이 과제를 통해 해당 URL들을 사용가능하게 만들어야 해요:
catalog/authors/— 작가 목록.catalog/author/<id>_ —<id>_라는 이름의 기본키를 이용한 작가의 세부 사항
URL mappers에 필요한 코드들과 view들은 ,사실상, 우리가 위에서 만들었던 Book 목록과 세부 사항 view들과 동일해야 합니다. template들은 다르겠지만, 비슷한 동작을 가지고 있을 겁니다.
참고:
- 작가 목록 페이지를 위한 URL mapper를 만들고나면, All authors base template에 있는 All authors 링크 또한 업데이트 해야될 필요를 느끼게 될 겁니다. 우리가 All books 링크 업데이트 때 했던, 수행 과정을 따라해주세요.
- 작가 세부 사항 페이지에 대한 URL mapper를 만들고나면, 당신은 book detail view template (/locallibrary/catalog/templates/catalog/book_detail.html) 또한 업데이트 해야 합니다. 그래야 작가 링크가 당신이 새로 만든 작가 세부 사항 페이지를 가리키거든요. (비어 있는 URL로 있기 보다는 말이죠). 굵게 되어 있는 부분을 template 내의 태그에 넣어주세요.
django
<p> <strong>Author:</strong> <a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a> </p>
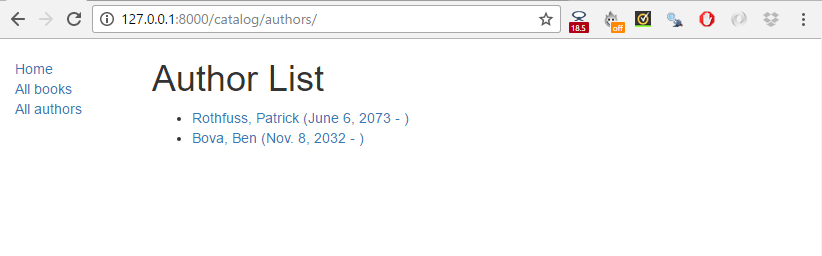
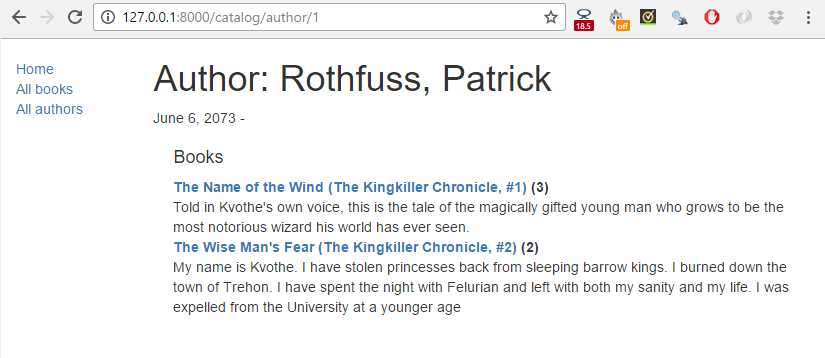
모두 마치면, 당신의 페이즈들은 아마 밑의 스크린샷과 비슷하게 보일 겁니다.
요약
축하합니다, 도서관의 가장 기본적인 기능들은 모두 끝났어요!
이번 글에서, 우리는 제네릭 클래스 기반의 list view와 detailv view에 대해서 배웠고, 이를 이용하여 책들과 작가들을 보여주기 위한 페이지를 만들었습니다. 이 과정중에 우리는 정규표현식을 이용하여 패턴 매칭을 하는 것도 배웠고, URL로 부터 데이터를 view에 보내는 것도 배웠습니다. 또한, template을 이용하는 몇 가지 트릭도 배웠죠. 마지막에는 list views에 어떻게 paginate를 할 수 있는지도 보았습니다. 이로 인해 우리는 레코드들이 많아져도 리스트를 관리할 수 있게 되었습니다.
다음 글에서 우리는 유저 계정을 지원하도록 도서관을 확장하고, 이를 통해 유저 인증, 권한, 세션, forms을 볼 것입니다.
See also
- Built-in class-based generic views (Django docs)
- Generic display views (Django docs)
- Introduction to class-based views (Django docs)
- Built-in template tags and filters (Django docs).
- Pagination (Django docs)