Visão geral do cliente-servidor
Agora que você conhece o propósito e os benefícios potenciais da programação do lado do servidor, examinaremos em detalhes o que acontece quando um servidor recebe uma "solicitação dinâmica" de um navegador. Como a maioria dos códigos do lado servidor do site lida com solicitações e respostas de maneiras semelhantes, isso o ajudará a entender o que você precisa fazer ao escrever a maior parte do seu próprio código.
| Pré requisitos: | Conhecimento básico em informática. Uma compreensão básica do que é um servidor web. |
|---|---|
| Objetivos: | Entender as interações entre cliente e servidor em um website dinâmico e, em particular, quais operações precisam ser realizadas pelo código no servidor. |
Não há código real em discussão porque ainda não escolhemos um framework web para escrever nosso código. No entanto essa discussão é muito relevante, porque o comportamento descrito deve ser implementado pelo seu código no servidor, independentemente de qual linguagem de programação ou framework web você escolha.
Web servers e HTTP (uma introdução)
Navegadores Web se comunicam com servidores Web usando o HyperTextTransfer Protocol (HTTP). Quando você clica em um link em uma página web, envia um formulário, ou faz uma pesquisa, o browser envia uma Requisição HTTP para o servidor.
A requisição inclui:
- Uma URL que identifica o servidor e o recurso de destino(e.g. por exemplo, um arquivo HTML, um determinado ponto de dados no servidor ou uma ferramenta a ser executada).
- Um método que define a ação necessária(por exemplo, para obter um arquivo ou para salvar ou atualizar alguns dados). Os diferentes métodos e suas ações associadas estão listados abaixo :
GET: Obtenha um recurso específico(por exemplo, um arquivo contendo informações sobre um produto ou uma lista de produtos) .POST: Crie um novo recurso(por exemplo, adicione um novo artigo a uma wiki, adicione um novo contato a um banco de dados e entre outros) .HEAD: Obtenha as informações de metadados sobre um recurso específico, sem obter o corpo, como o GET faria. Você pode, por exemplo, usar uma solicitação HEAD para descobrir a última vez que um recurso foi atualizado e, em seguida, usar a solicitação GET(mais "CARA") para baixar o recurso se ele tiver sido alterado.PUT: Atualize um recurso existente(ou crie um novo se ele não existir).DELETE: Apague um recurso específico.TRACE,OPTIONS,CONNECT,PATCH: Esses métodos são para tarefas menos comuns/avançadas, não os cobriremos por aqui.
- Informações adicionais podem ser codificadas com a solicitação(por exemplo, dados de formulário HTML). As informações podem ser codificadas como :
- Paramêtros de URL : Solicitações
GETcodificam dados na URL enviada ao servidor, adicionando pares de nome/valor ao final dela— por exemplo,http://mysite.com?name=Fred&age=11. Você sempre tem um ponto de interrogação (?) separando o resto da URL dos paramêtros de URL, um sinal de igual (=) separando cada nome de seu valor associado , e um "E" comercial (&) separando cada par. Os paramêtros URL são inerentemente inseguros, pois podem ser alterados pelos usuários e reenviados. Como resultado, os parâmetros de URL/ solicitações GET não são usados para solicitações que atualizam dados no servidor. POSTdata(dados de postagem). As solicitações POST adicionam novos recursos, cujos dados são codificados no corpo da solicitação.- Cookies do lado do cliente. Os cookies contêm dados de sessão sobre o cliente, incluindo chaves que o servidor pode usar para determinar seu status de login e permissões aos recursos.
- Paramêtros de URL : Solicitações
Os servidores da web aguardam as mensagens de solicitação do cliente, processam-nas quando chegam e respondem ao navegador da web com uma mensagem de resposta HTTP. A resposta contém( HTTP Response status code) um código de status de resposta HTTP que indica se a solicitação foi bem sucedida ou não (e.g. "200 OK" para sucesso, "404 Not Found" se o recurso não puder ser encontrado, "403 Forbidden" se o usuário não estiver autorizado para ver o recurso, etc). O corpo de uma resposta bem sucedida a uma solicitação GET conteria o recurso solicitado.
Quando uma página HTML é retornada, ela é processada pelo navegador da web. Como parte do processamento, o navegador pode descobrir links para outros recursos (por exemplo, uma página HTML geralmente faz referência a páginas JavaScript e CSS) e enviará solicitações HTTP separadas para baixar esses arquivos.
Os sites estáticos e dinâmicos (discutidos nas seções a seguir) usam exatamente o mesmo protocolo / padrões de comunicação.
Exemplo de requisição/resposta GET
Você pode fazer uma simples requisição GET clicando em um link ou buscando em um site (como uma simples ferramenta de pesquisa). Por exemplo, a requisição HTTP enviada quando você realiza uma busa na MDN pelo termo "cliente servidor visão geral" será muito parecido com o texto mostrado abaixo (não será identico porque partes da mensagem depente de seu navegador/configuração.
Nota: O formato das mensagens HTTP é definido em um "padrão da web" (RFC7230). Você não precisa saber esse nível de detalhe, mas pelo menos agora você sabe de onde vem tudo isso.
A requisição
Cada linha da solicitação contém informações sobre ela. A primeira parte é chamada de header, e contém informações úteis sobre o pedido, Da mesma forma que um HTML head contém informações úteis sobre um documento HTML(mas não o conteúdo real em si, que está no corpo):
GET https://developer.mozilla.org/en-US/search?q=client+server+overview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev HTTP/1.1 Host: developer.mozilla.org Connection: keep-alive Pragma: no-cache Cache-Control: no-cache Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Referer: https://developer.mozilla.org/en-US/ Accept-Encoding: gzip, deflate, sdch, br Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7 Accept-Language: en-US,en;q=0.8,es;q=0.6 Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _gat=1; _ga=GA1.2.1688886003.1471911953; ffo=true
A primeira e a segunda linhas contêm a maioria das informações sobre as quais falamos acima:
- O tipo de requisição (
GET). - A URL do recurso de destino (
/en-US/search). - Os parâmetros de URL (
q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev). - O site de destino(developer.mozilla.org).
- O final da primeira linha inclui uma string curta que identifica a versão e especifica o protocolo (
HTTP/1.1).
A linha final contém informações sobre os cookies do lado do cliente - você pode ver neste caso que o cookie inclui um id para gerenciar as sessões (Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; ...).
As linhas restantes contêm informações sobre o navegador usado e o tipo de respostas que ele pode manipular. Por exemplo, você pode ver aqui que:
- Meu navegador(
User-Agent) é o Mozilla Firefox (Mozilla/5.0). - Pode aceitar informações comprimidas gzip(
Accept-Encoding: gzip). - Pode aceitar o conjunto específico de caracteres (
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7) e idiomas (Accept-Language: de,en;q=0.7,en-us;q=0.3). - The
Refererline indica o endereço da página web que continha o link para este recurso (i.e. a origem da requisição,https://developer.mozilla.org/en-US/).
As solicitações HTTP também podem ter um corpo, mas está vazio neste caso
A resposta
A primeira parte da resposta para esta solicitação é mostrada abaixo. O header(cabeçalho) contém informações, como as seguintes:
- A primeira linha contém o código de resposta
200 OK, o que nos diz que a solicitação foi bem sucedida. - Podemos ver que a resposta é
text/htmlformatada (Content-Type). - Também podemos ver que ele usa o conjunto de caracteres UTF-8 (
Content-Type: text/html; charset=utf-8). - O head também nos diz o quão grande é (
Content-Length: 41823).
No final da mensagem vemos o conteúdo do corpo( body content) — que contém o HTML real retornado pela solicitação.
HTTP/1.1 200 OK
Server: Apache
X-Backend-Server: developer1.webapp.scl3.mozilla.com
Vary: Accept,Cookie, Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:11:31 GMT
Keep-Alive: timeout=5, max=999
Connection: Keep-Alive
X-Frame-Options: DENY
Allow: GET
X-Cache-Info: caching
Content-Length: 41823
<!DOCTYPE html>
<html lang="en-US" dir="ltr" class="redesign no-js" data-ffo-opensanslight=false data-ffo-opensans=false >
<head prefix="og: http://ogp.me/ns#">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<script>(function(d) { d.className = d.className.replace(/\bno-js/, ''); })(document.documentElement);</script>
...
O restante do header da resposta inclui informações sobre a resposta (por exemplo, quando ela foi gerada), o servidor e como ele espera que o navegador manipule a página(e.g. A linha X-Frame-Options: DENY diz ao navegador para não permitir que esta página seja incorporada em outros sites <iframe> ).
Exemplo de request(solicitação)/response(resposta) POST
Um HTTP POST é feito quando você envia um formulário contendo informações a serem salvas no servidor.
A requisição
O texto abaixo mostra a solicitação HTTP feita quando um usuário envia novos detalhes de perfil neste site. O formato de requisição é quase o mesmo que o exemplo de solicitação GET mostrado anteriormente, embora a primeira linha reconheça esta solicitação como um POST.
POST https:/en-US/profiles/hamishwillee/edit HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Content-Length: 432
Pragma: no-cache
Cache-Control: no-cache
Origin: https://developer.mozilla.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/profiles/hamishwillee/edit
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; _gat=1; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _ga=GA1.2.1688886003.1471911953; ffo=true
csrfmiddlewaretoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT&user-username=hamishwillee&user-fullname=Hamish+Willee&user-title=&user-organization=&user-location=Australia&user-locale=en-US&user-timezone=Australia%2FMelbourne&user-irc_nickname=&user-interests=&user-expertise=&user-twitter_url=&user-stackoverflow_url=&user-linkedin_url=&user-mozillians_url=&user-facebook_url=
A principal diferença é que o URL não possui parâmetros. Como você pode ver, as informações do formulário são codificadas no corpo da solicitação (por exemplo, o novo nome completo do usuário é definido usando: &user-fullname=Hamish+Willee).
A resposta
A resposta de solicitação é mostrada abaixo. O código de status "302 Found" diz ao navegador que a postagem foi bem sucedida, e que deve emitir uma segunda solicitação HTTP para carregar a página especificada no campo determinado( Location field). As informações são semelhantes às da resposta a uma solicitação GET .
HTTP/1.1 302 FOUND
Server: Apache
X-Backend-Server: developer3.webapp.scl3.mozilla.com
Vary: Cookie
Vary: Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:38:13 GMT
Location: https://developer.mozilla.org/en-US/profiles/hamishwillee
Keep-Alive: timeout=5, max=1000
Connection: Keep-Alive
X-Frame-Options: DENY
X-Cache-Info: not cacheable; request wasn't a GET or HEAD
Content-Length: 0
Nota: As respostas e solicitações HTTP mostradas nesse exemplo foram capturadas utilizando o aplicativo Fiddler , mas você pode obter informações semelhantes utilizando web sniffers (e.g. Websniffer) ou extensões de navegador como o HttpFox. Você pode tentar isso sozinho. Use qualquer uma das ferramentas vinculadas e navegue por um site e edite as informações de perfil para ver os diferentes tipos de solicitações e respostas. A maioria dos navegadores possuem ferramentas que monitoram solicitações de rede(por exemplo, a ferramenta Network Monitor no Firefox).
Sites estáticos
Um site estático é aquele que retorna o mesmo conteúdo codificado do servidor sempre que um recurso específico é solicitado. Por exemplo, se você tiver uma página sobre um produto em /static/myproduct1.html, esta mesma página será devolvida a todos os usuários. Se você adicionar outro produto semelhante ao seu site, você precisará adicionar outra página (e.g. myproduct2.html) e assim por diante. Isso pode começar a ficar realmente ineficiente - o que acontece quando você chega a milhares de páginas de produtos? Você repetiria muitos códigos em cada página (o modelo básico de página, estrutura, etc.) e, se quisesse alterar qualquer coisa na estrutura da página - como adicionar uma nova seção de "produtos relacionados", por exemplo -, tem que mudar cada página individualmente.
Nota: Os sites estáticos são excelentes quando você tem um pequeno número de páginas e deseja enviar o mesmo conteúdo para todos os usuários. No entanto, eles podem ter um custo significativo para manter à medida que o número de páginas aumenta.
Vamos recapitular como isso funciona, olhando novamente para o diagrama de arquitetura de site estático que vimos no último artigo.
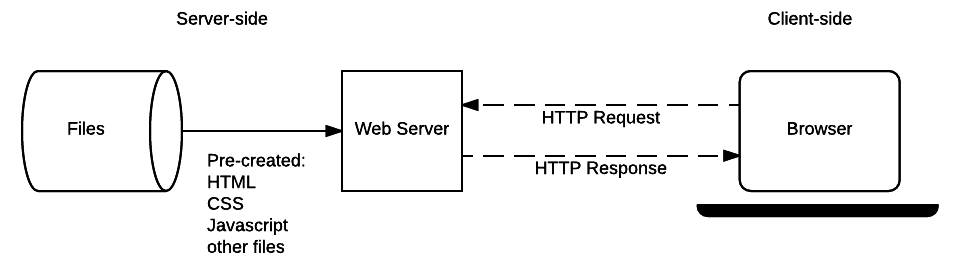
Quando o usuário deseja navegar em uma página, O navegador envia uma solicitação HTTP GET especificando o URL dessa página HTML. O servidor recupera o documento solicitado de seu sistema de arquivos e retorna uma resposta HTTP contendo o documento e um HTTP Response status code de "200 OK" (indicando). O servidor pode retornar um diferente código de status, por exemplo "404 Not Found" se o arquivo não estiver presente no servidor, ou "301 Moved Permanently" se o arquivo existe, mas foi redirecionado para um local diferente.
O servidor de um site estático sempre precisará processar solicitações GET, porque o servidor não armazena nenhum dado modificável. Ele também não altera suas respostas com base nos dados de solicitação HTTP (por exemplo, parâmetros de URL ou cookies).
No entanto, entender como os sites estáticos funcionam é útil ao aprender a programação do lado do servidor, porque os sites dinâmicos lidam com solicitações de arquivos estáticos (CSS, JavaScript, imagens estáticas etc.) exatamente da mesma maneira.
Sites dinâmicos
Um site dinâmico é aquele que pode gerar e retornar conteúdo com base no URL e nos dados de solicitação específicos (em vez de sempre retornar o mesmo arquivo embutido em código para um URL específico). Usando o exemplo de um site de produto, o servidor armazenaria "dados" do produto em um banco de dados em vez de arquivos HTML individuais. Ao receber uma solicitação HTTP GET para o produto , o servidor determina o ID do produto, busca os dados do banco de dados e, em seguida, constrói a página HTML para a resposta inserindo os dados em um modelo HTML. Isso tem grandes vantagens em relação a um site estático:
O uso de um banco de dados permite que as informações do produto sejam armazenadas com eficiência de uma forma facilmente extensível, modificável e pesquisável
O uso de modelos HTML torna muito fácil alterar a estrutura HTML, porque isso só precisa ser feito em um lugar, em um único modelo, e não em potencialmente milhares de páginas estáticas.
Anatomia de uma solicitação dinâmica
Esta seção fornece uma visão geral passo a passo da solicitação HTTP "dinâmica" e do ciclo de resposta, com base no que vimos no último artigo com muito mais detalhes. Para "manter as coisas reais", usaremos o contexto de um site de gerente de equipe esportiva, onde um treinador pode selecionar o nome e o tamanho da equipe em um formulário HTML e receber uma sugestão de "melhor escalação" para o próximo jogo.
O diagrama abaixo mostra os principais elementos do site do "treinador de equipe", juntamente com rótulos numerados para a sequência de operações quando o treinador acessa sua lista de "melhores equipes". As partes do site que o tornam dinâmico são o Web application(é assim que nos referiremos ao código do lado do servidor que processa solicitações HTTP e retorna respostas HTTP), o Banco de Dados, que contém informações sobre jogadores, times, treinadores e seus relacionamentos e os modelos HTML.
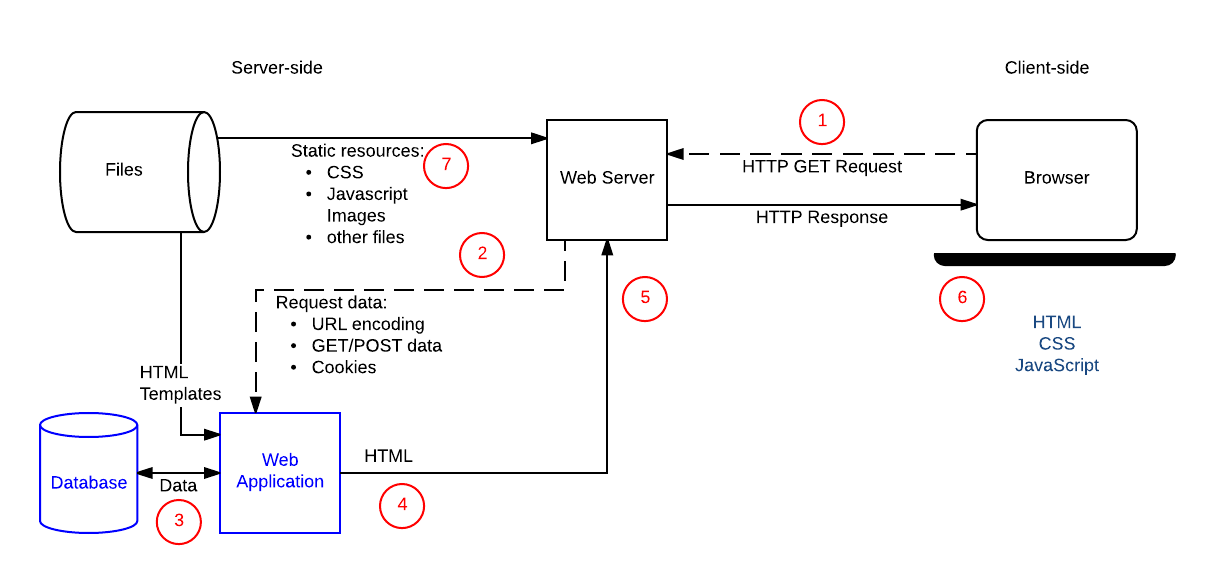
Após o treinador enviar o formulário com o nome da equipe e número de jogadores, a sequência de operações é:
- O navegador cria uma solicitação HTTP
GETpara o servidor usando a URL base para o recurso(/best) e codifica o número do time e do jogador como parâmetros de URL (e.g./best?team=my_team_name&show=11)ou como parte do padrão de URL (e.g./best/my_team_name/11/). A solicitaçãoGETé usada porque a solicitação está apenas buscando dados (não modificando dados). - O servidor da Web detecta que a solicitação é "dinâmica" e a encaminha ao Web application para o processamento (o servidor da Web determina como lidar com URLs diferentes com base nas regras de correspondência de padrões definidas em sua configuração).
- O Web Application identifica que a intenção da solicitação é obter a "lista da melhor equipe" com base no URL(
/best/)e descobre o nome da equipe necessária e o número de jogadores no URL. O Web application então obtém as informações necessárias do banco de dados (usando parâmetros "internos" adicionais para definir quais jogadores são os "melhores" e, possivelmente, também obtendo a identidade do treinador conectado a partir de um cookie do lado do cliente). - O Web application cria dinamicamente uma página HTML colocando os dados (do banco de dados) em espaços reservados dentro de um modelo HTML.
- O Web application retorna o HTML gerado para o navegador da Web (por meio do servidor da Web), junto com um código de status HTTP de 200 ("sucesso"). Se alguma coisa impedir que o HTML seja retornado, o Web application retornará outro código - por exemplo, "404" para indicar que a equipe não existe.
- O navegador da Web começará a processar o HTML retornado, enviando solicitações separadas para obter qualquer outro arquivo CSS ou JavaScript ao qual faça referência (consulte a etapa 7).
- O servidor da Web carrega arquivos estáticos do sistema de arquivos e os retorna ao navegador diretamente (novamente, o tratamento correto do arquivo é baseado nas regras de configuração e correspondência de padrão de URL).
Uma operação para atualizar um registro no banco de dados seria tratada de forma semelhante, exceto que, como qualquer atualização de banco de dados, a solicitação HTTP do navegador deve ser codificada como uma solicitação POST.
Fazendo outro trabalho
O trabalho de um Web application é receber solicitações HTTP e retornar respostas HTTP. Embora interagir com um banco de dados para obter ou atualizar informações sejam tarefas muito comuns, o código pode fazer outras coisas ao mesmo tempo ou não interagir com um banco de dados.
Um bom exemplo de uma tarefa adicional que um Web application pode realizar seria enviar um e-mail aos usuários para confirmar seu registro no site. O site também pode realizar registro ou outras operações.
Retornando algo diferente de HTML
O código do site do lado do servidor não precisa retornar snippets / arquivos HTML na resposta. Em vez disso, ele pode criar e retornar dinamicamente outros tipos de arquivos (texto, PDF, CSV, etc.) ou mesmo dados (JSON, XML, etc.).
A ideia de retornar dados a um navegador da web para que ele possa atualizar dinamicamente seu próprio conteúdo (AJAX) já existe há um bom tempo. Mais recentemente, os "aplicativos de página única" se tornaram populares, em que todo o site é escrito com um único arquivo HTML que é atualizado dinamicamente quando necessário. Os sites criados com esse estilo de aplicativo geram muitos custos computacionais do servidor para o navegador da web e podem resultar em sites que parecem se comportar muito mais como aplicativos nativos (altamente responsivos etc.).
Web frameworks simplificam a programação da Web do lado do servidor
Os frameworks web do lado do servidor tornam a escrita de código para lidar com as operações descritas acima muito mais fácil.
Uma das operações mais importantes que eles executam é fornecer mecanismos simples para mapear URLs de diferentes recursos / páginas para funções de manipulador específicas. Isso torna mais fácil manter o código associado a cada tipo de recurso separado. Também traz benefícios em termos de manutenção, pois você pode alterar a URL usada para entregar um determinado recurso em um único local, sem ter que alterar a função do manipulador.
Por exemplo, considere o seguinte código Django (Python) que mapeia dois padrões de URL para duas funções de visualização. O primeiro padrão garante que uma solicitação HTTP com um URL de recurso de /best será passado para uma função chamada index() no módulo views. Uma solicitação que tem o padrão "/best/junior", será passada para a fução view junior() .
# file: best/urls.py
#
from django.conf.urls import url
from . import views
urlpatterns = [
# example: /best/
url(r'^$', views.index),
# example: /best/junior/
url(r'^junior/$', views.junior),
]
Nota: Os primeiros parâmetros da função url() pode parecer um pouco estranho (e.g. r'^junior/$') porque eles usam uma técnica de correspondência de padrões chamada "expressões regulares"(RegEx, or RE). Você não precisa saber como as expressões regulares funcionam neste ponto, a não ser que elas nos permitam combinar padrões na URL (em vez dos valores codificados acima) e usá-los como parâmetros em nossas funções de visualização. Por exemplo, um RegEx realmente simples pode dizer "corresponde a uma única letra maiúscula, seguida por entre 4 e 7 letras minúsculas."
O framework web também torna mais fácil para uma função de visualização buscar informações do banco de dados. A estrutura de nossos dados é definida em modelos, que são classes Python que definem os campos a serem armazenados no banco de dados subjacente. Se tivermos um modelo denominado Team com um campo de "team_type", então podemos usar uma sintaxe de consulta simples para recuperar todas as equipes que possuem um tipo específico.
O exemplo abaixo obtém uma lista de todas as equipes que têm o exato (diferencia maiúsculas de minúsculas) team_type de "junior" —Observe o formato field name (team_type) seguido por sublinhado duplo e, em seguida, o tipo de correspondência a usar (neste caso exact). Existem muitos outros tipos de casos e podemos conectá-los em cadeia. Também podemos controlar a ordem e o número de resultados retornados.
#best/views.py
from django.shortcuts import render
from .models import Team
def junior(request):
list_teams = Team.objects.filter(team_type__exact="junior")
context = {'list': list_teams}
return render(request, 'best/index.html', context)
Depois da função junior() obter a lista de junior teams, é chamada a função render() , passando o original HttpRequest, um modelo HTML e um objeto de "contexto" que define as informações a serem incluídas no modelo. A função render() é uma função de conveniência que gera HTML usando um contexto e um modelo HTML e o retorna em um objeto HttpResponse .
Obviamente, os frameworks da Web podem ajudá-lo em muitas outras tarefas. Discutiremos muitos outros benefícios e algumas opções populares de estrutura da web no próximo artigo.
Resumo
Neste ponto, você deve ter uma boa visão geral das operações que o código do lado do servidor deve realizar e conhecer algumas das maneiras pelas quais uma framework Web do lado do servidor pode tornar isso mais fácil.
Em um módulo a seguir, vamos ajudá-lo a escolher o melhor Web Framework para seu primeiro site.