Клиент-сервер
Теперь, когда вы знаете цель и потенциальные преимущества программирования на стороне сервера, мы подробно рассмотрим, что происходит, когда сервер получает «динамический запрос» от браузера. Поскольку большая часть серверного кода веб-сайта обрабатывает запросы и ответы аналогичным образом, это поможет вам понять, что нужно делать при написании большей части собственного кода.
| Перед стартом: | Базовая компьютерная грамотность. Базовое понимание того, что такое веб-сервер. |
|---|---|
| Цель: | Изучить взаимодействие между клиентом и сервером на динамическом веб-сайте и, в частности, узнать, какие действия нужно произвести в коде серверной части. |
В обсуждении нет реального кода, поскольку мы ещё не выбрали, какой именно веб-фреймворк будем использовать для написания нашего кода! Тем не менее, это обсуждение всё ещё очень актуально, поскольку описанное поведение должно быть реализовано вашим серверным кодом независимо от того, какой язык программирования или веб-фреймворк вы выберите.
Веб-серверы и HTTP (для начинающих)
Веб-браузеры взаимодействуют с веб-серверами при помощи протокола передачи гипертекста (HTTP). Когда вы кликаете на ссылку на странице, заполняете форму или производите поиск, браузер отправляет на сервер HTTP-запрос.
Этот запрос включает:
- Путь (URL), который определяет целевой сервер и ресурс (например, HTML-файл, конкретная точка данных на сервере или запускаемый инструмент).
- Метод, который определяет необходимое действие (например, получить файл, сохранить или обновить какие-либо данные). Различные методы/команды и связанные с ними действия перечислены ниже:
GET– получить определённый ресурс (например, HTML-файл, содержащий информацию о товаре или список товаров).POST– создать новый ресурс (например, добавить новую статью на вики, добавить новый контакт в базу данных).HEAD– получить метаданные об определённом ресурсе без получения содержания, как это делает запросGET. Например, вы можете использовать запросHEAD, чтобы узнать, когда ресурс в последний раз обновлялся, и только потом использовать (более «затратный») запросGET, чтобы загрузить сам ресурс, если он был изменён.PUT– обновить существующий ресурс (или создать новый, если таковой не существует).DELETE– удалить определённый ресурс.TRACE,OPTIONS,CONNECT,PATCH– эти команды используются для менее популярных/более сложных задач, поэтому пока мы не будем их рассматривать.
- Дополнительная информация может быть закодирована в запросе (например, данные HTML-формы). Информация может быть закодирована как:
- URL-параметры:
GETзапросы зашифровывают данные в URL-адресе, который отправляется на сервер, путём добавления пар имя/значение в его конец, например,http://mysite.com?name=Fred&age=11. В этом случае всегда ставится знак вопроса (?), отделяющий основную часть URL-адреса от URL-параметров, знак равно (=), отделяющий каждое имя от соответствующего ему значения, и амперсанд (&), разделяющий пары. URL-параметры, по своей сути, «небезопасны», так как могут быть изменены пользователями и затем отправлены повторно. В результате, URL-параметры /GETзапросы не используются для запросов, которые обновляют данные на сервере. POSTданные.POSTзапросы добавляют новые ресурсы, данные которых зашифрованы в теле самого запроса.- Куки-файлы клиентской части. Куки-файлы содержат данные сессий о клиенте, включая ключи, которые сервер может использовать для определения статуса его авторизации и разрешения/права доступа к ресурсам.
- URL-параметры:
Веб-серверы ожидают сообщений с запросами от клиентов, обрабатывают их, когда они приходят и отвечают веб-браузеру через сообщение с HTTP-ответом. Ответ содержит Код статуса HTTP-ответа, который показывает, был ли запрос успешным (например, «200 OK» означает успех, «404 Not Found» если ресурс не может быть найден, «403 Forbidden», если пользователь не имеет права просматривать ресурс, и т. д.). Тело успешного ответа на запрос GET будет содержать запрашиваемый ресурс.
После того как HTML-страница возвращена, она отрисовывается браузером. Во время этого браузер может обнаружить ссылки на другие ресурсы (например, HTML-страница обычно ссылается на JavaScript и CSS-файлы) и послать отдельные HTTP-запросы для загрузки этих файлов.
Как статические, так и динамические веб-сайты (речь о которых идёт в следующих разделах) используют точно такой же протокол/шаблоны обмена данными.
Пример GET запроса/ответа
Вы можете сформировать простой GET запрос кликнув по ссылке или через поиск по сайту (такой как страница поисковой системы). Например, HTTP-запрос, отправленный во время выполнения запроса "client server overview" на сайте MDN, будет во многом похож на текст ниже (он не будет идентичным, потому что части сообщения зависят от вашего браузера/настроек).
Примечание: Формат HTTP сообщения определён в «веб-стандарте» (RFC7230). Вам не нужно знать этот уровень детализации, но, по крайней мере, теперь вы знаете, откуда это появилось!
Запрос
Каждая строка запроса содержит информацию о запросе. Первая часть называется заголовок и содержит важную информацию о запросе, точно так же, как HTML head содержит важную информацию о HTML-документе (но не содержимое документа, которое расположено внутри тэга "body"):
GET https://developer.mozilla.org/en-US/search?q=client+server+overview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev HTTP/1.1 Host: developer.mozilla.org Connection: keep-alive Pragma: no-cache Cache-Control: no-cache Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Referer: https://developer.mozilla.org/en-US/ Accept-Encoding: gzip, deflate, sdch, br Accept-Language: en-US,en;q=0.8,es;q=0.6 Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _gat=1; _ga=GA1.2.1688886003.1471911953; ffo=true
Первая и вторая строки содержат большую часть информации, о которой говорилось выше:
- Тип запроса (
GET). - URL целевого ресурса (
/en-US/search). - URL-параметры (
q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev). - Целевой/хост-веб-сайт (developer.mozilla.org).
- Конец первой строки также содержит короткую строку, идентифицирующую версию протокола (
HTTP/1.1).
Последняя строка содержит информацию о клиентских куки — в данном случае можно увидеть куки, включающие id для управления сессиями (Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; ...).
Оставшиеся строки содержат информацию об используемом браузере и о видах ответов, которые он может обработать. Например, здесь вы можете увидеть:
- Мой браузер (
User-Agent) — Mozilla Firefox (Mozilla/5.0). - Он может принимать информацию, упакованную в gzip (
Accept-Encoding: gzip). - Он может принимать указанные кодировки (
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7) и языков (Accept-Language: de,en;q=0.7,en-us;q=0.3). - Строка
Refererидентифицирует адрес веб-страницы, содержащей ссылку на этот ресурс (то есть источник оригинального запроса,https://developer.mozilla.org/en-US/).
HTTP-запрос может также содержать body, но в данном случае этого нет.
Ответ
Первая часть ответа на запрос показана ниже. Заголовок содержит следующую информацию:
- Первая строка содержит код ответа
200 OK, говорящий о том, что запрос выполнен успешно. - Мы можем видеть, что ответ имеет
text/htmlформат (Content-Type). - Также мы видим, что ответ использует кодировку UTF-8 (
Content-Type: text/html; charset=utf-8). - Заголовок также содержит длину ответа (
Content-Length: 41823).
В конце сообщения мы видим содержимое body, содержащее HTML-код возвращаемого ответа.
HTTP/1.1 200 OK
Server: Apache
X-Backend-Server: developer1.webapp.scl3.mozilla.com
Vary: Accept,Cookie, Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:11:31 GMT
Keep-Alive: timeout=5, max=999
Connection: Keep-Alive
X-Frame-Options: DENY
Allow: GET
X-Cache-Info: caching
Content-Length: 41823
<!DOCTYPE html>
<html lang="en-US" dir="ltr" class="redesign no-js" data-ffo-opensanslight=false data-ffo-opensans=false >
<head prefix="og: http://ogp.me/ns#">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<script>(function(d) { d.className = d.className.replace(/\bno-js/, ''); })(document.documentElement);</script>
...
Остальная часть заголовка ответа содержит информацию об ответе (например, когда он был сгенерирован), сервере и о том, как он ожидает, что браузер обработает страницу (например, строка X-Frame-Options: DENY говорит браузеру не допускать внедрения этой страницы, если она будет внедрена в <iframe> (en-US) на другом сайте).
Пример POST запроса/ответа
HTTP POST создаётся, когда вы отправляете форму, содержащую информацию, которая должна быть сохранена на сервере.
Запрос
В приведённом ниже тексте показан HTTP-запрос, сделанный когда пользователь загружает новые данные профиля на этом сайте. Формат запроса почти такой же, как пример запроса GET, показанный ранее, хотя первая строка идентифицирует этот запрос как POST.
POST https:/en-US/profiles/hamishwillee/edit HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Content-Length: 432
Pragma: no-cache
Cache-Control: no-cache
Origin: https://developer.mozilla.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/profiles/hamishwillee/edit
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; _gat=1; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _ga=GA1.2.1688886003.1471911953; ffo=true
csrfmiddlewaretoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT&user-username=hamishwillee&user-fullname=Hamish+Willee&user-title=&user-organization=&user-location=Australia&user-locale=en-US&user-timezone=Australia%2FMelbourne&user-irc_nickname=&user-interests=&user-expertise=&user-twitter_url=&user-stackoverflow_url=&user-linkedin_url=&user-mozillians_url=&user-facebook_url=
Основное различие заключается в том, что URL-адрес не имеет параметров. Как вы можете видеть, информация из формы закодирована в теле запроса (например, новое полное имя пользователя устанавливается с использованием: &user-fullname=Hamish+Willee).
Ответ
Ответ от запроса показан ниже. Код состояния «302 Found» сообщает браузеру, что сообщение обработано, и что необходим второй HTTP-запрос для загрузки страницы, указанной в поле Location. В остальном информация аналогична информации для ответа на запрос GET .
HTTP/1.1 302 FOUND
Server: Apache
X-Backend-Server: developer3.webapp.scl3.mozilla.com
Vary: Cookie
Vary: Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:38:13 GMT
Location: https://developer.mozilla.org/en-US/profiles/hamishwillee
Keep-Alive: timeout=5, max=1000
Connection: Keep-Alive
X-Frame-Options: DENY
X-Cache-Info: not cacheable; request wasn't a GET or HEAD
Content-Length: 0
Примечание: HTTP-ответы и запросы, показанные в этих примерах, были захвачены с помощью приложения Fiddler, но вы можете получить аналогичную информацию с помощью веб-снифферов (например, http://web-sniffer.net/) или с помощью расширений браузера, таких как HttpFox. Вы можете попробовать это сами. Воспользуйтесь любым из предложенных инструментов, а затем перейдите по сайту и отредактируйте информацию профиля, чтобы увидеть различные запросы и ответы. В большинстве современных браузеров также есть инструменты, которые отслеживают сетевые запросы (например, инструмент Network Monitor в Firefox).
Статические сайты
Статический сайт — это тот, который возвращает тот же жёсткий кодированный контент с сервера всякий раз, когда запрашивается конкретный ресурс. Например, если у вас есть страница о товаре в /static/myproduct1.html, эта же страница будет возвращена каждому пользователю. Если вы добавите ещё один подобный товар на свой сайт, вам нужно будет добавить ещё одну страницу (например, myproduct2.html) и так далее. Это может стать действительно неэффективным — что происходит, когда вы попадаете на тысячи страниц товаров? Вы повторяли бы много кода на каждой странице (основной шаблон страницы, структуру и т. д.), И если бы вы захотели изменить что-либо в структуре страницы — например, добавить новый раздел «связанные товары» — тогда вам придётся менять каждую страницу отдельно.
Примечание: Статические сайты превосходны, когда у вас небольшое количество страниц и вы хотите отправить один и тот же контент каждому пользователю. Однако их обслуживание может потребовать значительных затрат по мере увеличения количества страниц.
Давайте вспомним, как это работает, снова взглянув на диаграмму архитектуры статического сайта, на которую мы смотрели в последней статье.
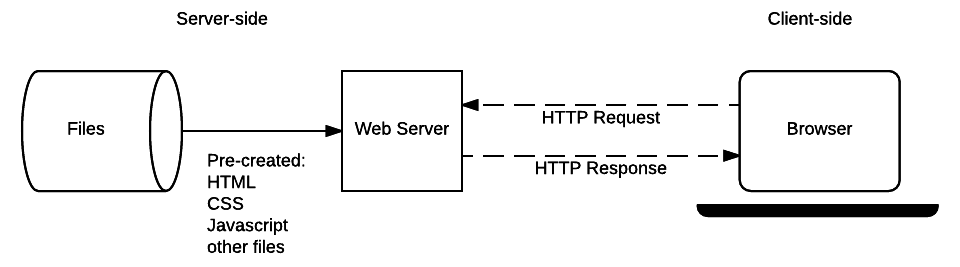
Когда пользователь хочет перейти на страницу, браузер отправляет HTTP-запрос GET с указанием URL-адреса его HTML-страницы. Сервер извлекает запрошенный документ из своей файловой системы и возвращает HTTP-ответ, содержащий документ и код состояния HTTP Response status code 200 OK (успех). Сервер может вернуть другой код состояния, например, «404 Not Found», если файл отсутствует на сервере или «301 Moved Permanently», если файл существует, но был перемещён в другое место.
Серверу для статического сайта нужно будет только обрабатывать GET-запросы, потому что сервер не сохраняет никаких модифицируемых данных. Он также не изменяет свои ответы на основе данных HTTP-запроса (например, URL-параметров или файлов cookie).
Понимание того, как работают статические сайты, тем не менее полезно при изучении программирования на стороне сервера, поскольку динамические сайты точно так же обрабатывают запросы для статических файлов (CSS, JavaScript, статические изображения и т. д.).
Динамические сайты
Динамический сайт — это тот, который может генерировать и возвращать контент на основе конкретного URL-адреса запроса и данных (а не всегда возвращать один и тот же жёсткий код для определённого URL-адреса). Используя пример сайта товара, сервер будет хранить «данные» товара в базе данных, а не отдельные HTML-файлы. При получении GET-запроса для товара сервер определяет идентификатор товара, извлекает данные из базы данных и затем создаёт HTML-страницу для ответа, вставляя данные в HTML-шаблон. Это имеет большие преимущества перед статическим сайтом:
Использование базы данных позволяет эффективно хранить информацию о товаре с помощью легко расширяемого, изменяемого и доступного для поиска способа.
Использование HTML-шаблонов позволяет очень легко изменить структуру HTML, потому что это нужно делать только в одном месте, в одном шаблоне, а не через потенциально тысячи статических страниц.
Анатомия динамического запроса
В этом разделе представлен пошаговый обзор «динамического» цикла HTTP-запроса и ответа, основываясь на том, что мы рассмотрели в последней статье, с гораздо более подробной информацией. Чтобы не отдаляться от практики, мы будем использовать контекст веб-сайта менеджера спортивной команды, где тренер может выбрать имя своей команды и размер команды в HTML-форме и вернуться к предлагаемому «лучшему составу» для своей следующей игры.
На приведённой ниже диаграмме показаны основные элементы веб-сайта «team coach», а также пронумерованные ярлыки для последовательности операций, когда тренер обращается к списку «лучших команд». Частями сайта, которые делают его динамичным, являются веб-приложение (так мы будем ссылаться на серверный код, обрабатывающий HTTP-запросы и возвращающие HTTP-ответы), база данных, которая содержит информацию об игроках, командах, тренерах и их отношениях, и HTML-шаблоны.
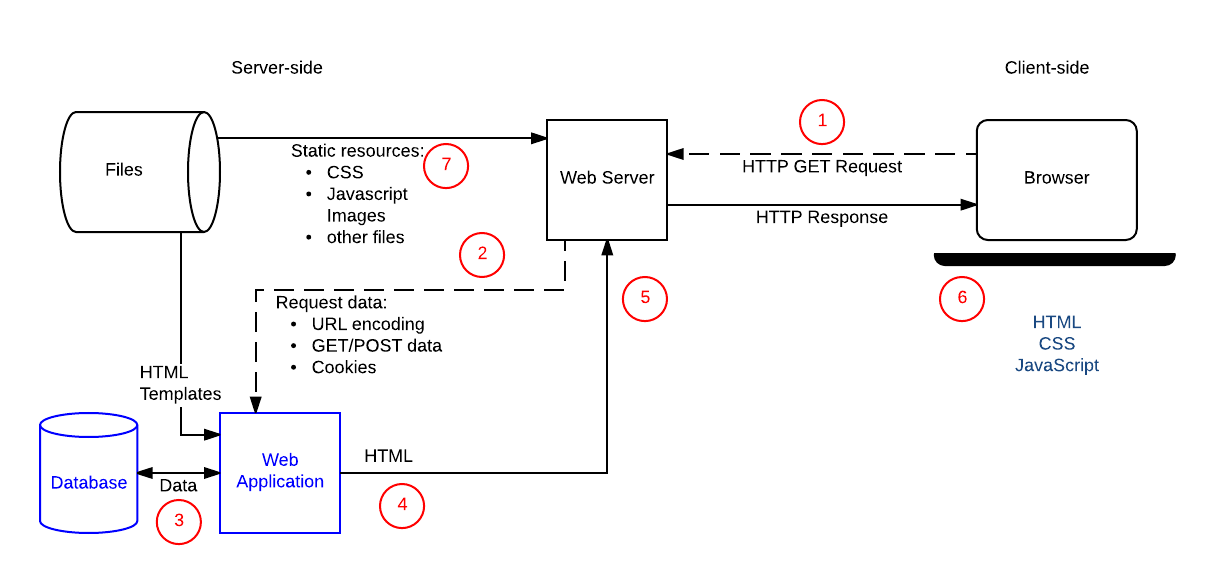
После того, как тренер отправит форму с именем команды и количеством игроков, последовательность операций будет следующей:
- Веб-браузер отправит HTTP-запрос
GETна сервер с использованием базового URL-адреса ресурса (/best) и кодирования номера команды и игрока в форме URL-параметров (например,/best?team=my_team_name&show=11)или как часть URL-адреса (например,/best/my_team_name/11/). ЗапросGETиспользуется, потому что речь идёт только о запросе выборки данных (а не об их изменении). - Веб-сервер определяет, что запрос является «динамическим» и пересылает его в веб-приложение для обработки (веб-сервер определяет, как обрабатывать разные URL-адреса на основе правил сопоставления шаблонов, определённых в его конфигурации).
- Веб-приложение определяет, что цель запроса состоит в том, чтобы получить «лучший список команд» на основе URL (
/best/) и узнать имя команды и количество игроков из URL-адреса. Затем веб-приложение получает требуемую информацию из базы данных (используя дополнительные «внутренние» параметры, чтобы определить, какие игроки являются «лучшими», и, возможно, определяя личность зарегистрированного тренера из файла cookie на стороне клиента). - Веб-приложение динамически создаёт HTML-страницу, помещая данные (из базы данных) в заполнители внутри HTML-шаблона.
- Веб-приложение возвращает сгенерированный HTML в веб-браузер (через веб-сервер) вместе с кодом состояния HTTP 200 («успех»). Если что-либо препятствует возврату HTML, веб-приложение вернёт другой код, например, «404», чтобы указать, что команда не существует.
- Затем веб-браузер начнёт обрабатывать возвращённый HTML, отправив отдельные запросы, чтобы получить любые другие файлы CSS или JavaScript, на которые он ссылается (см. шаг 7).
- Веб-сервер загружает статические файлы из файловой системы и возвращает их непосредственно в браузер (опять же, правильная обработка файлов основана на правилах конфигурации и сопоставлении шаблонов URL).
Операция по обновлению записи в базе данных будет обрабатываться аналогичным образом, за исключением того, что, как и любое обновление базы данных, HTTP-запрос из браузера должен быть закодирован как запрос POST.
Выполнение другой работы
Задача веб-приложения — получать HTTP-запросы и возвращать HTTP-ответы. Хотя взаимодействие с базой данных для получения или обновления информации является очень распространённой задачей, код может делать другие вещи одновременно или вообще не взаимодействовать с базой данных.
Хорошим примером дополнительной задачи, которую может выполнять веб-приложение, является отправка электронной почты пользователям для подтверждения их регистрации на сайте. Сайт также может выполнять протоколирование или другие операции.
Возвращение чего-то другого, кроме HTML
Серверный код сайта может возвращать не только HTML-фрагменты и файлы в ответе. Он может динамически создавать и возвращать другие типы файлов (текст, PDF, CSV и т. д.) или даже данные (JSON, XML и т. д.).
Идея вернуть данные в веб-браузер, чтобы он мог динамически обновлять свой собственный контент (AJAX) существует довольно давно. Совсем недавно «Одностраничные приложения» стали популярными, где весь сайт написан с одним HTML-файлом, который динамически обновляется по мере необходимости. Веб-сайты, созданные с использованием приложений такого рода, переносят большие вычислительные затраты с сервера на веб-браузер и приводят к тому, что веб-сайты, ведут себя больше как нативные приложения (очень отзывчивые и т. д.).
Веб-фреймворки упрощают веб-программирование на стороне сервера
Веб-фреймворки на стороне сервера делают написание кода для обработки описанных выше операций намного проще.
Одной из наиболее важных операций, которые они выполняют, является предоставление простых механизмов для сопоставления URL-адресов для разных ресурсов/страниц с конкретными функциями обработчика. Это упрощает сохранение кода, связанного с каждым типом ресурса, отдельно от остального. Это также имеет преимущества с точки зрения обслуживания, поскольку вы можете изменить URL-адрес, используемый для доставки определённой функции в одном месте, без необходимости изменять функцию обработчика.
Для примера рассмотрим следующий код Django (Python), который связывает два URL-шаблона с двумя функциями просмотра. Первый шаблон проверяет, что HTTP-запрос с URL-адресом ресурса /best будет передан функции с именем index() в модуле views. Запрос, который имеет шаблон «/best/junior», вместо этого будет передан функции просмотра junior().
# file: best/urls.py
#
from django.conf.urls import url
from . import views
urlpatterns = [
# example: /best/
url(r'^$', views.index),
# example: /best/junior/
url(r'^junior/$', views.junior),
]
Примечание: Первые параметры в функциях url() могут выглядеть немного необычно (например, r'^junior/$', потому что они используют метод сопоставления шаблонов под названием «регулярные выражения» (RegEx или RE). Вам не нужно знать, как работают регулярные выражения на этом этапе, кроме того, что они позволяют нам сопоставлять шаблоны в URL-адресе (а не жёстко закодированные значения выше) и использовать их в качестве параметров в наших функциях просмотра. В качестве примера, действительно простой RegEx может говорить «соответствовать одной заглавной букве, за которой следуют от 4 до 7 строчных букв».
Веб-фреймворк также упрощает функцию просмотра для получения информации из базы данных. Структура наших данных определяется в моделях, которые являются классами Python, которые определяют поля, которые должны храниться в основной базе данных. Если у нас есть модель с именем Team с полем «team_type», мы можем использовать простой синтаксис запроса, чтобы получить все команды, имеющие определённый тип.
В приведённом ниже примере представлен список всех команд, у которых есть точный (с учётом регистра) team_type «junior» («младший») — обратите внимание на формат: имя поля (team_type), за которым следует двойной знак подчёркивания, а затем тип соответствия для использования (в этом случае exact («точное»)). Существует много других типов соответствия, и мы можем объединить их. Мы также можем контролировать порядок и количество возвращаемых результатов.
#best/views.py
from django.shortcuts import render
from .models import Team
def junior(request):
list_teams = Team.objects.filter(team_type__exact="junior")
context = {'list': list_teams}
return render(request, 'best/index.html', context)
После того, как функция junior() получает список младших команд, она вызывает функцию render(), передавая исходный HttpRequest, HTML-шаблон и объект «context», определяющий информацию, которая должна быть включена в шаблон. Функция render() — это функция удобства, которая генерирует HTML с использованием контекста и HTML-шаблона и возвращает его в объект HttpResponse.
Очевидно, что веб-фреймворки могут помочь вам в решении многих других задач. В следующей статье мы обсудим намного больше преимуществ и некоторые популярные варианты веб-фреймворков.