客户端服务端交互概述
既然你已经了解了服务器端编程的目的和潜在的好处,接下来我们将非常细致地去说明当服务器接收到了来自浏览器的“动态请求”时到底发生了什么。因为大多数的服务器端代码通过相似的方式来处理请求并做出响应,这将帮助你理解当编写你自己的大量代码时你需要做什么。
| 前提: | 基本电脑素养、对于什么是网络服务器的基本了解 |
|---|---|
| 目标: | 理解在动态网站中的客户端 - 服务器端交互过程,尤其是服务器端代码需要承担的工作 |
到目前为止的讨论中还没有真正的代码,因为我们还没有选择一个 web 框架来写我们的代码呢!然而这个讨论仍旧十分重要,因为我们描述的行为必须通过你的服务器端代码来实现,不管你选择什么编程语言和 web 框架。
网络服务器和 HTTP(入门)
网络浏览器通过超文本标记语言传输协议(HTTP)与网络服务器(web servers)。当你在网页上点击一个链接、提交一个表单、或者进行一次搜索的时候,浏览器发送一个 HTTP 请求给服务器。
这个请求包含:
- 一个用来识别目标服务器和资源(比如一个 HTML 文档、存储在服务器上的一个特定的数据、或者一个用来运行的工具等)的 URL。
- 一个定义了请求行为的方法(比如,获得一个文档或者上传某些数据)。不同的方法/动作以及与他们相关的行为罗列如下:
GET:获取一份指定(比如一个包含了一个产品或者一系列产品相关信息的 HTML 文档)。POST:创建一份新的资源(比如给 wiki 增加一片新的文章、给数据库增加一个新的节点)。HEAD: 获取有关指定资源的元数据信息,而不会得到像 GET 的内容部分。例如,你可以使用 HEAD 请求来查找上次更新资源的时间,然后仅使用(更“昂贵”)GET 请求下载资源(如果已更改)。PUT:更新一份已经存在的资源(或者在该资源不存在的情况下创建一份新的)。DELETE:删除指定的资源。TRACE、OPTIONS、CONNECT、PATCH:这些动作是为一些不常见任务设计的,因此我们在这里的讲解不会涉及到它们。
- 额外的信息可以和请求一起被编码(比如 HTML 表单数据)。信息可以被编码成如下:
- URL 参数:GET 请求通过在 URL 末尾增加的键值对,来编码包含在发送给服务器的 URL 中的数据——比如,
http://mysite.com?name=Fred&age=11,你经常会用到问号(?)来将 URL 剩余的部分和 URL 参数分隔开来,一个赋值符号(=)将名称和与之相关的值分隔开来,然后一个“&”符号分割不同的键值对。当他们被用户改变然后提交时,URL 参数具有与生俱来地“不安全性”。因此,一个 URL 参数或者 GET 请求是不会用来在服务器上更新数据的。 - POST 数据:POST 请求会增加新的资源,这些数据将会在请求体中编码。
- 客户端 cookie:cookies 包含与客户相关的会话数据,服务器可以用这些数据来判断用户的登录状态以及用户是否有访问资源的权限。
- URL 参数:GET 请求通过在 URL 末尾增加的键值对,来编码包含在发送给服务器的 URL 中的数据——比如,
网络服务器等待来自客户的请求信息,当请求到达时处理它们,然后发给浏览器 HTTP 响应消息。回应包含一个 HTTP 响应状态码(HTTP Response status code)来暗示请求是否成功 (比如 "200 OK" 连接成功, "404 Not Found" 资源没有找到,"403 Forbidden" 用户没有被授权查看资源,等等). 一个成功的响应主体,会包含 GET 请求所请求的资源。
当一个 HTML 页面被返时,页面会被网络浏览器呈现出来。作为处理工作的一部分,浏览器会发现指向其他资源的链接(比如,一个 HTML 页面通常会参考 Javascript 和 CSS 页面),并且会发送独立的 HTTP 请求来下载这些文件。
静态网站和动态网站(在接下来的部分讨论到的)正是使用同一种通信协议/模式
GET 请求/响应举例
你可以通过点击一个链接或者在网站进行一次搜索(比如搜索引擎的首页)做出一次简单的 GET 请求。比如,当你在 MDN 上进行一次对“客户端概览”词条的搜索时,HTTP 请求就被发送出去了,你将会看到正如下面一样被展示出来的文本信息(展示出来的信息不一定是相同的,因为其中一部分信息还取决于你的浏览器)。
备注: HTTP 消息的格式是在“网络标准”(RFC7230)中定义的。你不需要知道这个标准的细节,但是现在你至少得知道所有这些是来自哪儿的!
请求
每一行请求都包含着相关信息。第一部分被称为header,并且包含着关于这个请求的有用信息,同样地一个HTML head包含着关于 HTML 文档的有用信息(但是却没有自身的实际内容,内容在主体里面)。
GET https://developer.mozilla.org/en- US/search?q=client+server+overview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev HTTP/1.1 Host: developer.mozilla.org Connection: keep-alive Pragma: no-cache Cache-Control: no-cache Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Referer: https://developer.mozilla.org/en-US/ Accept-Encoding: gzip, deflate, sdch, br Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7 Accept-Language: en-US,en;q=0.8,es;q=0.6 Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _gat=1; _ga=GA1.2.1688886003.1471911953; ffo=true
第一行和第二行包含了我们在上面讨论过的大部分信息
- 请求类型(GET)。
- 目标资源的 URL(
/en-US/search)。 - URL 参数(
q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev)。 - 目标网站(developer.mozilla.org)。
- 第一行的末尾也包含了一个简短的包含了标识协议版本的字符串(
HTTP/1.1)。
最后一行包括一些关于客户端 cookies 的信息——你可以看到在这种情况下 cookies 包含一个为处理远程会话准备的 ID(Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; ...)。
剩余几行包含着所使用的浏览器以及浏览器所能处理的回应类型等信息。比如,你可以在下面看到这些相关信息:
- 我的浏览器上 (
User-Agent) 是火狐 (Mozilla/5.0). - 它可以接收 gzip 压缩信息 (
Accept-Encoding: gzip). - 它可以接收的具体编码类型 (
Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7) 和语言 (Accept-Language: de,en;q=0.7,en-us;q=0.3). - The
Refererline 提示包含资源链接的网络地址 (或者说请求的来源是https://developer.mozilla.org/en-US/).
请求也可以有一个请求体,不过在这个例子中请求的请求体是空的。
回应
针对这个请求的回应的第一部分内容展示如下。The header 包含了如下信息:
- 第一行包括了回应状态码 200 OK,这告诉我们请求是成功的。
- 我们可以看到回应是文本
html格式的(Content-Type)。 - 我们也可以看到它使用的是 UTF-8 字符集 (
Content-Type: text/html; charset=utf-8). - The head 也告诉我们它有多大 (
Content-Length: 41823).
在消息的末尾我们可以看到主体内容——包含了针对请求返回的真实的 HTML。
HTTP/1.1 200 OK
Server: Apache
X-Backend-Server: developer1.webapp.scl3.mozilla.com
Vary: Accept,Cookie, Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:11:31 GMT
Keep-Alive: timeout=5, max=999
Connection: Keep-Alive
X-Frame-Options: DENY
Allow: GET
X-Cache-Info: caching
Content-Length: 41823
<!DOCTYPE html>
<html lang="en-US" dir="ltr" class="redesign no-js" data-ffo-opensanslight=false data-ffo-opensans=false >
<head prefix="og: http://ogp.me/ns#">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<script>(function(d) { d.className = d.className.replace(/\bno-js/, ''); })(document.documentElement);</script>
...
header 的剩余部分还包括一些回应的其他信息(比如回应在什么时候生成的),有关服务器的信息,还有它期望浏览器如何处理这个包(比如, X-Frame-Options: DENY 告诉浏览器不允许这个网页嵌入在其他网站的 HTML 元素<iframe>上。
POST 请求/响应举例
当你提交一个表单,并且希望表单所包含的信息存储到服务器的时候,你就生成了一次 HTTP POST 请求。
请求
下面的文本展示了当用户在网站上提交新的文件的时候,生成的一个 HTTP 请求的格式和之前展示的 GET 请求是非常相似的,只是第一行标识这个请求为 POST。
POST https:/en-US/profiles/hamishwillee/edit HTTP/1.1
Host: developer.mozilla.org
Connection: keep-alive
Content-Length: 432
Pragma: no-cache
Cache-Control: no-cache
Origin: https://developer.mozilla.org
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: https://developer.mozilla.org/en-US/profiles/hamishwillee/edit
Accept-Encoding: gzip, deflate, br
Accept-Language: en-US,en;q=0.8,es;q=0.6
Cookie: sessionid=6ynxs23n521lu21b1t136rhbv7ezngie; _gat=1; csrftoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT; dwf_section_edit=False; dwf_sg_task_completion=False; _ga=GA1.2.1688886003.1471911953; ffo=true
csrfmiddlewaretoken=zIPUJsAZv6pcgCBJSCj1zU6pQZbfMUAT&user-username=hamishwillee&user-fullname=Hamish+Willee&user-title=&user-organization=&user-location=Australia&user-locale=en-US&user-timezone=Australia%2FMelbourne&user-irc_nickname=&user-interests=&user-expertise=&user-twitter_url=&user-stackoverflow_url=&user-linkedin_url=&user-mozillians_url=&user-facebook_url=
最主要的不同在于 URL 不再包含任何参数。正如你所见,表单提交的信息被编码后放入消息主体中了。(比如:使用以下命令设置新的用户全名:&user-fullname=Hamish+Willee)
响应
请求的响应如下。状态码"302 FOUND"告知浏览器,服务端已收到它提交的 post 请求,它必须再发出第二个 HTTP 请求来加载Location字段中指定的页面。对于其他方面的信息含义,则与GET请求的响应信息类似。
HTTP/1.1 302 FOUND
Server: Apache
X-Backend-Server: developer3.webapp.scl3.mozilla.com
Vary: Cookie
Vary: Accept-Encoding
Content-Type: text/html; charset=utf-8
Date: Wed, 07 Sep 2016 00:38:13 GMT
Location: https://developer.mozilla.org/en-US/profiles/hamishwillee
Keep-Alive: timeout=5, max=1000
Connection: Keep-Alive
X-Frame-Options: DENY
X-Cache-Info: not cacheable; request wasn't a GET or HEAD
Content-Length: 0
备注: 上面展示的 HTTP 请求和响应式通过 Fiddler 软件来捕获的,你也可以得到相似的信息通过使用网络嗅探器(比如http://web-sniffer.net/)或者使用浏览器扩展例如 HttpFox。你可以自己尝试一下。使用任何一个上面链接的工具,浏览一个站点并修改主要信息来观察不同的请求和响应。更多的现代浏览器拥有网络监控工具(例如,在 Firefox 上的 Network Monitor 工具)。
静态网站
静态网站是指每当请求一个特定的资源时,会从服务器返回相同的硬编码内容。因此,例如,如果你在 /static/myproduct1.html 有一个关于产品的页面,则该页面将返回给每个用户。如果你添加另一个类似的产品到你的网站,你将需要添加另一个页面(例如 myproduct2.html )等。这可能开始变得非常低效:当你访问数千个产品页面时会发生什么——你会在每个页面(基本的页面模板,结构等等)上重复很多代码,如果你想改变页面结构的任何东西,比如添加一个新的“相关产品”部分,必须单独更改每个页面。
备注: 当你有少量页面时,向每个用户发送相同的内容时,静态网站是最佳选择,然而随着页面数量的增加,它们的维护成本也会很高。
让我们回顾一下在上一篇文章中看到的静态网站架构图,看看它是如何工作的。
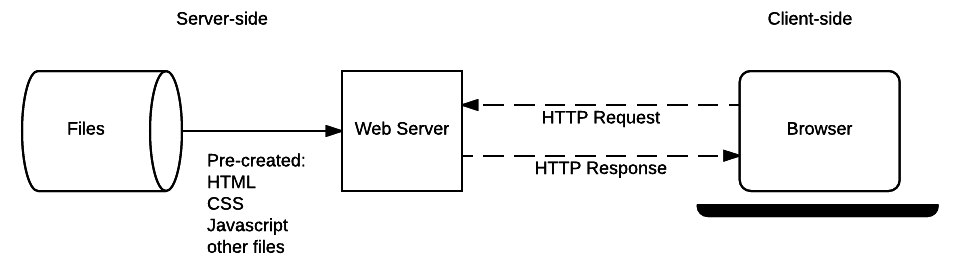
当用户想要导航到页面时,浏览器会发送一个指定 HTML 页面的 URL 的 HTTP 的GET请求。
服务器从它的文件系统中检索所请求的文档,并返回包含文档和 HTTP 响应状态码“200 OK”(表示成功) 的 HTTP 响应。服务器可能会返回一个不同的状态码,例如,"404 Not Found"表明文件不在服务器上,或者"301 Moved Permanently"表明如果文件存在,则被重定向到另一个位置。
静态站点的服务器只需要处理 GET 请求,因为服务器不存储任何可修改的数据。它也不会根据 HTTP 请求数据(例如 URL 参数或 cookie)更改响应。
了解静态站点如何工作在学习服务器端编程时非常有用,因为动态站点以完全相同的方式处理对静态文件 (CSS、JavaScript、静态图像等) 的请求。
动态网站
动态站点可以根据特定的请求 URL 和数据生成和返回内容 (而不是总是返回同一个 URL 的硬编码文件)。使用产品网页的示例,服务器将把产品“数据”存储在数据库中,而不是单独的 HTML 文件。当接收到一个产品的 HTTP GET 请求时,服务器将确定产品 ID,从数据库中获取数据,然后通过将数据插入到 HTML 模板中来构造响应的 HTML 页面。与静态站点相比,这有很大的优势
通过使用数据库,可以有效地将产品信息存储在易于扩展、可修改和可搜索的方式中。
使用 HTML 模板可以很容易地改变 HTML 结构,因为这只需要在一个模板中的某一处地方完成,而不需要跨越数千个静态页面。
剖析动态请求
本节将逐步概述“动态”HTTP 请求和响应周期,以更详细的内容构建我们在上一篇文章中所看到的内容。为了“让事情保持真实”,我们将使用一个体育团队经理网站的情景,在这个网站上,教练可以用 HTML 表单选择他们的球队名称和球队规模,并为他们的下一场比赛中获得建议的“最佳阵容”。
下面的图表显示了“球队教练”网站的主要元素,以及当教练访问他们的“最佳团队”列表时,操作序列的编号。使其动态的站点的部分是 Web 应用程序(这就是我们将如何引用处理 HTTP 请求并返回 HTTP 响应的服务器端代码)数据库,该数据库包含关于球员、球队、教练及其关系以及 HTML 模板的信息。
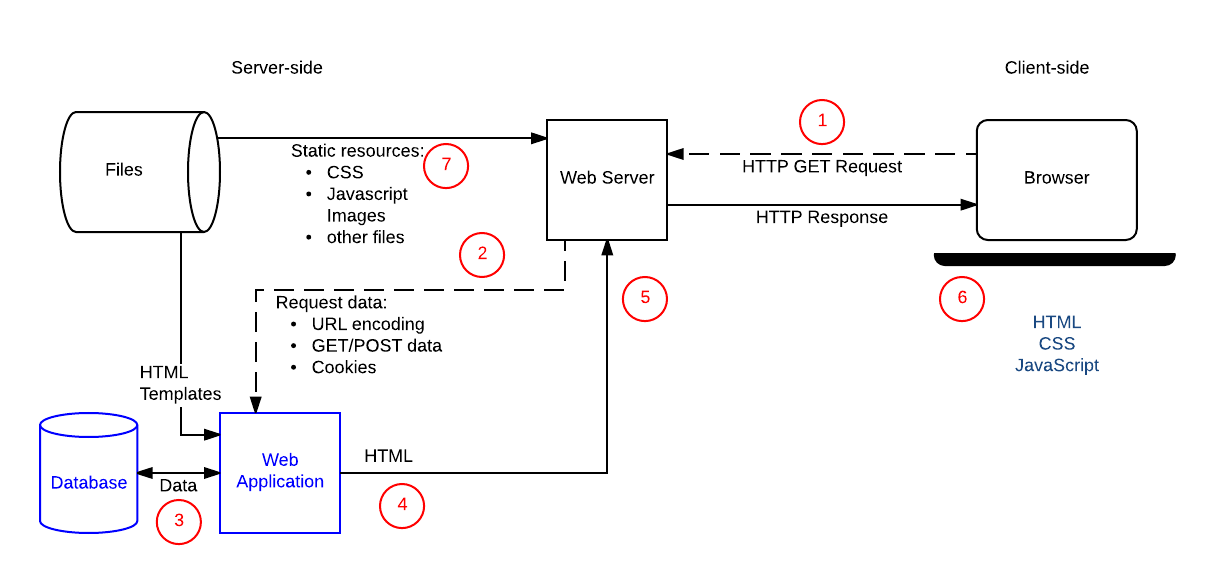
在教练提交球员名单和球员人数后,其操作顺序为:
- Web 浏览器使用资源的基本 URL(
/best)来创建一个 HTTPGET请求,将球队和球员编号附加到 URL 后面作为参数(例如/best?team = my_team_name&show = 11)或作为 URL 地址的一部分(例如/best/my_team_name/11/)。使用GET请求是因为请求只是获取数据(而不是修改数据)。 - Web 服务器检测到请求是“动态的”,并将其转发给 Web 应用程序(Web Application)进行处理(Web 服务器根据其配置中定义的模式匹配规则确定如何处理不同的 URL)。
- Web 应用程序(Web Application)确定请求的意图是根据 URL(
/best/)获得“最佳团队列表”,并从 URL 中找出所需的球队名称和球员人数。然后,Web 应用程序(Web Application)从数据库中获取所需的信息(使用额外的“内部”参数来定义哪些球员是“最好”的,并且可能还从客户端 cookie 获得登录教练的身份)。 - Web 应用程序(Web Application)通过将数据(来自数据库)放入 HTML 模板中的占位符中动态地创建 HTML 页面。
- Web 应用程序(Web Application)将生成的 HTML(通过 Web 服务器)和 HTTP 状态代码 200(“成功”)返回到 Web 浏览器。如果有任何东西阻止 HTML 被返回,那么 Web 应用程序将返回另一个状态代码 - 例如“404”来表示球队不存在。
- 然后,Web 浏览器将开始处理返回的 HTML,发送单独的请求以获取其引用的任何其他 CSS 或 JavaScript 文件(请参阅步骤 7)。
- Web 服务器从文件系统加载静态文件,并直接返回到浏览器(同样,正确的文件处理基于配置规则和 URL 模式匹配)。
在服务器中,更新数据库中的记录的操作将被类似地与上述过程一样处理,但是更新数据库的这一类的操作,应该指定来自浏览器的 HTTP 请求为POST请求。
完成其他工作
Web 应用程序(Web Application)的工作是接收 HTTP 请求并返回 HTTP 响应。虽然与数据库交互以获取或更新信息是非常常见的功能,但是代码也可能同时做其他事情,甚至不与数据库交互。
一个 Web 应用程序(Web Application)可能执行的额外任务的一个很好的例子就是发送一封电子邮件给用户,以确认他们在网站上的注册。该网站也可能执行日志记录或其他操作。
返回 HTML 以外的内容
服务器端网站代码并非只能在响应中返回 HTML 代码片段/文件。它可以动态地创建和返回其他类型的文件(text,PDF,CSV 等)甚至是数据(JSON,XML 等)。
将数据返回到 Web 浏览器以便它可以动态更新自己的内容(AJAX)的想法实现已经有相当长的一段时间了。最近,“单页面应用程序”已经变得流行起来,整个网站用一个 HTML 文件编写,在需要时动态更新。使用这种风格的应用程序创建的网站将大量的计算成本从服务器推向网络浏览器,并可能导致网站表现出更像本地应用程序(高度响应等)。
web 框架简化服务器端的 web 编程
服务器端 web 框架使得编写解决我们上面描述的操作的代码变得简单得多。
web 框架可以提供的一个最重要的功能就是,提供简单的机制,以将不同的资源和页面定位到具体的处理函数。这使得保持代码和各个不同形式的资源的联系变得简单。它也非常利于代码的维护,因为你可以直接改变在一个地方用来传输特定功能的 URL,而不用改变处理函数。
举个例子,我们来思考一下下面的 Django(python) 代码,这些代码将两个 URL 地址定位到两个页面。第一个地址确保了,一个包含了 /best/ URL 的 HTTP 请求,可以被传递到一个在views模块的被命名为index()的函数。一个含有"/best/junior"的请求则会被传递到junior()视图函数。
# file: best/urls.py
#
from django.conf.urls import url
from . import views
urlpatterns = [
# example: /best/
url(r'^$', views.index),
# example: /best/junior/
url(r'^junior/$', views.junior),
]
备注: 在url()函数中的第一个参数可能看起来有点古怪 (比如r'^junior/$) 因为他们使用一个叫做“正则表达式”(RegEx, or RE) 的字符匹配机制。在这里,你还不需要知道正则表达式是如何工作的,除了要知道它们是如何允许我们在 URL 中匹配到字符的 (而不是像上面的硬编码) 并且知道如何在我们的视图函数中将它们用作参数。举个例子,一个真正简单的正则表达式可能会说“匹配一个大写字母,后面跟着 4 到 7 个小写字母”。
Web 框架还可以轻松地使用查看函数,从数据库获取信息。我们的数据结构是在模型中定义的,模型是定义要存储在底层数据库中的字段的 Python 类。如果我们有一个名为 Team 的模型,其中有一个“team_type”字段,那么我们可以使用一个简单的查询语法来取回所有具有特定类型的球队。
下面的例子得到了所有字段 team_type(区分大小写)为“junior”的所有球队的列表 - 注意格式:字段名称(team_type),后面跟着双下划线,然后是使用的匹配类型)。还有很多其他的匹配类型,我们可以组合他们。我们也可以控制返回结果的顺序和数量。
#best/views.py
from django.shortcuts import render
from .models import Team
def junior(request):
list_teams = Team.objects.filter(team_type__exact="junior")
context = {'list': list_teams}
return render(request, 'best/index.html', context)
junior()函数获得少年组列表后,它调用render()函数,传递原始的 HttpRequest,一个 HTML 模板和一个定义要包含在模板中的信息的“context”对象。 render()函数是一个方便的函数,它使用上下文和 HTML 模板生成 HTML,并将其返回到 HttpResponse 对象中
显然地 web 框架可以帮助你解决很多问题。我们在下一篇文章里将会大量讨论这些好处和一些流行的 web 框架。