WebGPU API
Experimental: これは実験的な機能です。
本番で使用する前にブラウザー互換性一覧表をチェックしてください。
安全なコンテキスト用: この機能は一部またはすべての対応しているブラウザーにおいて、安全なコンテキスト (HTTPS) でのみ利用できます。
WebGPU API は、ウェブ開発者が下層のシステムの GPU (Graphics Processing Unit) を使用し、高効率の計算をしたり、ブラウザーでレンダーできる複雑な画像を描画したりすることを可能にします。
WebGPU は WebGL の後継で、最近の GPU とのより良い互換性を提供し、汎用 GPU 計算に対応し、操作を速くし、さらに高度な GPU の機能へのアクセスを可能にします。
概念と使用法
2011 年頃に最初に登場した後、WebGL がグラフィックの能力の面でウェブに革命を起こしたといえます。WebGL は OpenGL ES 2.0 グラフィックライブラリーの JavaScript への移植であり、ウェブページがレンダリング計算をデバイスの GPU に直接渡し、超高速で処理させ、結果を <canvas> 要素内に描画することを可能にします。
WebGL と WebGL シェーダーのコードを書くのに用いられる GLSL 言語は複雑なので、WebGL アプリケーションをより簡単に書けるようにするためにいくつかの WebGL ライブラリーが作られました。有名な例としては Three.js、Babylon.js、PlayCanvas などがあります。開発者はこれらのツールを用い、没入感のあるウェブベースの 3D ゲーム、ミュージックビデオ、訓練やモデリングのツール、VR や AR の体験、などを作ってきました。
しかし、WebGL には修正が必要な根本的な問題点がいくつかあります。
- WebGL がリリースされて以降、新世代のネイティブ GPU API が登場しました。最も人気があるのは Microsoft の Direct3D 12、Apple の Metal、The Khronos Group の Vulkan です。これらは多くの新機能を提供します。OpenGL のアップデートはもう計画されておらず、WebGL も同様なので、これらの新機能は何も導入されません。一方、WebGPU は進歩し、新機能が追加されるでしょう。
- WebGL は完全にグラフィックを描画し、それをキャンバスに描画するというユースケースに基づいており、汎用 GPPU (GPGPU) 計算をあまり上手く扱うことができません。GPGPU 計算は機械学習モデルをベースにするものなど、多くの異なるユースケースでどんどん重要になってきています。
- 3D グラフィックアプリケーションは、同時にレンダリングするオブジェクトの数と新しいレンダリング機能の活用の両面で、負荷が高くなってきています。
WebGPU は、最近の GPU API と互換性があり、より「webby」な感じがする新しい汎用アーキテクチャを提供し、これらの問題点を解決します。グラフィックのレンダリングに対応しているとともに、GPGPU 計算にもよく対応しています。CPU 側での個別のオブジェクトの描画は劇的に軽くなり、計算ベースのパーティクルや、色効果、鮮明化、被写界深度シミュレーションなどの後処理フィルターなどの最近の GPU のレンダリング機能にも対応します。さらに、カリングやスキン付きモデルの変換などの重い計算を直接 GPU で扱うことができます。
一般モデル
デバイスの GPU と WebGPU API を実行しているウェブブラウザーの間には、いくつかの抽象化レイヤーがあります。WebGPU の学習を開始する際、これらを理解することは有用です。
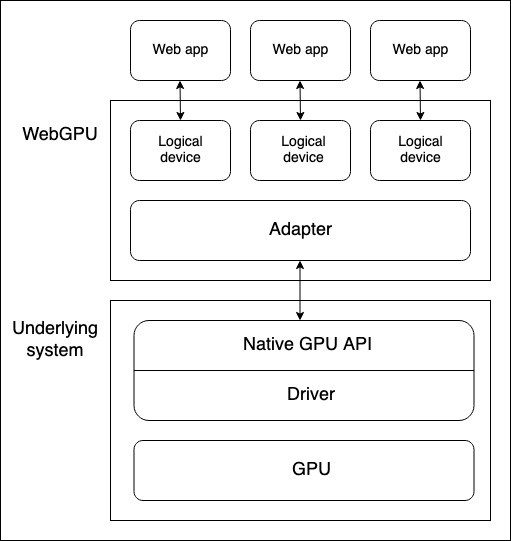
- GPU がある物理デバイス。ほとんどのデバイスには GPU が 1 個だけありますが、複数あるデバイスもあります。以下の異なる GPU の種類が利用可能です。
- 統合 GPU: CPU と同じ基板にあり、メモリーを共有します。
- 個別 GPU: 独自の基板にあり、CPU からは分離されています。
- ソフトウェア「GPU」: CPU 上で実装されています。
メモ: 上記の図では、GPU が 1 個だけあるデバイスを仮定しています。
- OS の一部であるネイティブ GPU API (たとえば macOS 上の Metal) は、ネイティブアプリケーションが GPU の機能を用いることができるプログラミングインターフェイスです。API 命令がドライバーを通じて GPU に送られ、結果を受け取ります。上記の図ではネイティブ API およびドライバーが 1 個だけあるデバイスを仮定していますが、システムが GPU とやり取りするための複数のネイティブ OS API やドライバーを持つことも可能です。
- ブラウザーの WebGPU 実装は、ネイティブ GPU API ドライバーを通じた GPU とのやり取りを扱います。WebGPU のアダプターが、あなたのコード上で下層のシステムで利用可能な物理 GPU とドライバーを効率よく表します。
- 論理デバイスは、単一のウェブアプリケーションが分離された方法で GPU の機能にアクセスできるようにする抽象化です。論理デバイスは、多重化の機能を提供する必要があります。物理デバイスの GPU は多くのアプリケーションで用いられ、並行で処理を行います。この中には多くのウェブアプリケーションが含まれる可能性があります。それぞれのウェブアプリケーションは、セキュリティおよびロジック上の理由で、隔離された状態で WebGPU にアクセスできる必要があります。
デバイスへのアクセス
論理デバイスは、GPUDevice (en-US) オブジェクトインスタンスで表され、ウェブアプリケーションが WebGPU のすべての機能にアクセスする基礎となります。デバイスへのアクセスは、以下の手順で行われます。
Navigator.gpuプロパティ (もしくは、ワーカーから WebGPU の機能を用いる場合はWorkerNavigator.gpu) が現在のコンテキスト用のGPUオブジェクトを返します。GPU.requestAdapter()メソッドを通じてアダプターにアクセスします。このメソッドは省略可能な設定オブジェクトを受け取り、たとえば高パフォーマンスのアダプターや低消費電力のアダプターを要求することができます。これが無い場合は、デバイスはデフォルトのアダプターへのアクセスを提供し、これはほとんどの目的に十分適するでしょう。GPUAdapter.requestDevice()によりデバイスを要求できます。このメソッドは、(ディスクリプターと呼ばれる) オプションオブジェクトも受け取り、これにより論理デバイスに期待する詳細な機能や制限を指定できます。これが無い場合は、返されるデバイスは合理的な汎用のスペックを持ち、これはほとんどの用途に適します。
これらにいくつかの機能検出チェックを加えると、上記の手順は以下のようにして実現できます。
async function init() {
if (!navigator.gpu) {
throw Error("WebGPU に対応していません。");
}
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw Error("WebGPU アダプターの要求に失敗しました。");
}
const device = await adapter.requestDevice();
//...
}
パイプラインとシェーダー: WebGPU アプリケーションの構造
パイプラインは、プログラムの処理を実現するために実行するプログラマブルなステージが入る論理的な構造です。現在、WebGPU では以下の 2 種類のパイプラインを扱うことができます。
- レンダーパイプラインはグラフィックをレンダリングします。
<canvas>要素に描画することが多いですが、オフスクリーンでグラフィックをレンダリングすることもできます。これには以下の 2 個のメインステージがあります。- バーテックスステージ: バーテックスシェーダーが GPU に渡された位置データを受け取り、回転、変換、射影などの指定の効果を適用することで 3D 空間内の頂点群の位置を決定します。そして、頂点は三角形 (レンダリングされるグラフィックの基礎となる部品) などのプリミティブに組み立てられ、GPU によって描画を行うキャンバスのどのピクセルをカバーするかを特定するためにラスタライズされます。
- : フラグメントステージ: バーテックスシェーダーによって生成されたプリミティブでカバーされた各ピクセルの色をフラグメントシェーダーが計算します。これらの計算には、表面の詳細を提供する (テクスチャ形式の) 画像や、仮想光源の位置や色などの入力がよく用いられます。
- コンピュートパイプラインは一般の計算用です。コンピュートパイプラインは 1 個の計算ステージからなります。このステージでは、コンピュートシェーダーが一般のデータを受け取り、指定の数のワークグループで並列計算を行い、結果を 1 個以上のバッファーで返します。バッファーには任意の種類のデータを置けます。
上記で言及されたシェーダーは、GPU で処理される命令の集合です。WebGPU のシェーダーは WebGPU Shader Language (WGSL) と呼ばれる Rust 風の低レベルの言語で書かれます。
WebGPU アプリケーションを構築するにはいくつかの異なる方法がありますが、このプロセスはおそらく以下の手順を含むでしょう。
- シェーダーモジュールの生成: WGSL でシェーダーコードを書き、1 個以上のシェーダーモジュールにパッケージ化します。
- キャンバスコンテキストの取得と設定:
<canvas>要素のwebgpuコンテキストを取得し、GPU 論理デバイスでどのような画像をレンダリングするかの情報を設定します。この手順は、コンピュートパイプラインのみを用いる場合など、アプリケーションが画像を出力しない場合は不要です。 - データを格納したリソースの生成: パイプラインで処理するデータは、アプリケーションからアクセスするため、GPU バッファーまたはテクスチャーに格納される必要があります。
- パイプラインの生成: 必要なデータ構造、バインディング、シェーダー、リソースの配置を含めて要求するパイプラインを詳細に記述するパイプラインディスクリプターを定義し、それに基づいてパイプラインを生成します。ここでの基本デモには 1 個のパイプラインのみがありますが、自明でないアプリケーションは通常異なる目的のための複数のパイプラインを持ちます。
- 計算またはレンダリングパスの実行: これはいくつかのサブ手順からなります。
- 実行用に GPU に渡すコマンド一式をエンコードするコマンドエンコーダーを生成します。
- 計算またはレンダリングコマンドを発行するパスエンコーダーオブジェクトを生成します。
- 使用するパイプラインの指定、必要なデータの取得元となるバッファーの指定、(レンダーパイプラインの場合は) 行う描画操作の数の指定、などを行うコマンドを実行します。
- コマンドリストをファイナライズし、コマンドバッファーにカプセル化します。
- 論理デバイスのコマンドキューを通して、コマンドバッファーを GPU に送信します。
以下の節では、レンダーパイプラインの基本デモを解析し、必要なものを探索できるようにします。その後、コンピュートパイプラインの基本の例も解析し、レンダーパイプラインとの違いに注目します。
レンダーパイプラインの基本
レンダリング基本デモでは、<canvas> 要素に青一色の背景を用意し、その上に三角形を描画します。
シェーダーモジュールの生成
ここでは以下のシェーダーコードを用います。バーテックスシェーダーステージ (@vertex ブロック) は、位置と色が格納されたデータのチャンクを受け取り、位置に基づいて頂点を配置し、色を補間し、これらのデータをフラグメントシェーダーステージに渡します。フラグメントシェーダーステージ (@fragment ブロック) は、バーテックスシェーダーステージからデータを受け取り、指定の色に基づいて頂点の色を決定します。
const shaders = `
struct VertexOut {
@builtin(position) position : vec4f,
@location(0) color : vec4f
}
@vertex
fn vertex_main(@location(0) position: vec4f,
@location(1) color: vec4f) -> VertexOut
{
var output : VertexOut;
output.position = position;
output.color = color;
return output;
}
@fragment
fn fragment_main(fragData: VertexOut) -> @location(0) vec4f
{
return fragData.color;
}
`;
メモ: ここでのデモではシェーダーコードをテンプレートリテラルに格納していますが、WebGPU プログラムに渡すテキストとして取得しやすい場所ならどこに格納することもできます。たとえば、シェーダーを <script> 要素の中に格納し、Node.textContent を用いて内容を取り出す方法もよく用いられます。WGSL 用の正しい MIME タイプは text/wgsl です。
シェーダーコードを WebGPU で利用できるようにするには、シェーダーコードをディスクリプターオブジェクトのプロパティとして GPUDevice.createShaderModule() (en-US) に渡し、GPUShaderModule (en-US) の中に格納する必要があります。これは、たとえば以下のように行います。
const shaderModule = device.createShaderModule({
code: shaders,
});
キャンバスコンテキストの取得と設定
レンダーパイプラインでは、グラフィックのレンダリング先を指定する必要があります。ここでは、画面上の <canvas> 要素への参照を取得し、引数 webgpu を HTMLCanvasElement.getContext() に渡すことで、GPU コンテキスト (GPUCanvasContext (en-US) のインスタンス) を返してもらいます。
そして、レンダリング情報の取得元となる GPUDevice (en-US)、テクスチャーの形式、半透明のテクスチャーをレンダリングする際に用いるアルファモードが格納されたオプションオブジェクトを GPUCanvasContext.configure() (en-US) に渡すことで、コンテキストを設定します。
const canvas = document.querySelector("#gpuCanvas");
const context = canvas.getContext("webgpu");
context.configure({
device: device,
format: navigator.gpu.getPreferredCanvasFormat(),
alphaMode: "premultiplied",
});
メモ: 使用するテクスチャーの形式を決めるベストプラクティスは、GPU.getPreferredCanvasFormat() メソッドを用いることです。これは、ユーザーのデバイス用の最も効率的な形式 (bgra8unorm または rgba8unorm) を選択します。
バッファを生成して三角形データを書き込む
次に、WebGPU が利用できる形式で、WebGPU にデータを提供します。データは最初 Float32Array で提供され、ここには三角形の各頂点について 8 個のデータ (位置の X, Y, Z, W および色の R, G, B, A) が格納されています。
const vertices = new Float32Array([
0.0, 0.6, 0, 1, 1, 0, 0, 1, -0.5, -0.6, 0, 1, 0, 1, 0, 1, 0.5, -0.6, 0, 1, 0,
0, 1, 1,
]);
しかし、ここで問題に直面します。データを GPUBuffer (en-US) に格納する必要があります。裏側では、この種類のバッファーは GPU のコアに非常に密接に統合されたメモリーに保存され、期待される高効率の処理を可能にします。副作用として、このメモリーはブラウザーなどのホストシステム上で実行されているプロセスからはアクセスできません。
GPUBuffer (en-US) は GPUDevice.createBuffer() (en-US) を呼び出すことにより生成できます。すべてのデータを格納できるよう、配列 vertices の長さと同じサイズを指定します。さらに、バッファーを頂点バッファーとして、およびコピー先として用いることを示す VERTEX および COPY_DST 使用法フラグを指定します。
const vertexBuffer = device.createBuffer({
size: vertices.byteLength, // 頂点を格納するのに十分な大きさにする
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
コンピュートパイプラインの例でデータを GPU から JavaScript に読み戻すために用いるようなマッピング操作を用いてデータを GPUBuffer に乗せることもできます。しかし、ここでは使いやすい GPUQueue.writeBuffer() (en-US) メソッドを用います。このメソッドは、書き込み先のバッファー、書き込み元のデータソース、それぞれのオフセット値、そして書き込むデータのサイズ (ここでは配列全体の長さを指定した) を引数としてとります。すると、ブラウザーは最も効率のよい方法でデータの書き込みを処理します。
device.queue.writeBuffer(vertexBuffer, 0, vertices, 0, vertices.length);
レンダーパイプラインの定義と生成
これでデータをバッファーに配置できました。準備の次のパートは、レンダリングに用いることができるパイプラインを実際に生成することです。
まず最初に、頂点データで必要なレイアウトを記述するオブジェクトを生成します。これは以前に配列 vertices およびバーテックスシェーダーステージで見たものを完全に記述します。すなわち、各頂点が位置と色のデータを持ちます。どちらも (WGSL の vec4<f32> 型に対応する) float32x4 形式でフォーマットされ、色データは各頂点で 16 バイトのオフセットから始まります。arrayStride はストライド、すなわち各頂点を構成するバイト数を指定し、stepMode はデータを頂点ごとに読み取るべきであることを指定します。
const vertexBuffers = [
{
attributes: [
{
shaderLocation: 0, // 位置
offset: 0,
format: "float32x4",
},
{
shaderLocation: 1, // 色
offset: 16,
format: "float32x4",
},
],
arrayStride: 32,
stepMode: "vertex",
},
];
次に、レンダーパイプラインステージの構成を指定するディスクリプターオブジェクトを生成します。両方のシェーダーステージで関係するコードがある GPUShaderModule (en-US) (shaderModule)、および各ステージのエントリーポイントとなる関数の名前を指定します。
さらに、バーテックスシェーダーステージでは頂点データに求める状態を提供する vertexBuffers オブジェクトを提供し、フラグメントシェーダーステージでは (以前キャンバスコンテキストの設定で指定した形式と一致する) 指定のレンダリング形式を表す色ターゲットの状態の配列を提供します。
さらに、primitive 状態も指定します。これは今回は単に描画するプリミティブの種類を表します。さらに、layout を auto に設定します。layout プロパティはパイプラインの実行中に用いるすべての GPU リソース (バッファーやテクスチャーなど) のレイアウト (構造、用途、種類) を定義します。より複雑なアプリケーションでは、これは GPUPipelineLayout (en-US) オブジェクトの形式になるでしょう。これは GPUDevice.createPipelineLayout() (en-US) を用いて生成でき (コンピュートパイプラインの基本で例を見ることができます)、GPU がどうすればパイプラインを最も効率よく実行できるかを事前に決定できるようにします。しかし、ここでは値 auto を指定し、パイプラインにシェーダーコードで定義されたバインディングに基づいて暗黙のバインドグループレイアウトを生成させます。
const pipelineDescriptor = {
vertex: {
module: shaderModule,
entryPoint: "vertex_main",
buffers: vertexBuffers,
},
fragment: {
module: shaderModule,
entryPoint: "fragment_main",
targets: [
{
format: navigator.gpu.getPreferredCanvasFormat(),
},
],
},
primitive: {
topology: "triangle-list",
},
layout: "auto",
};
最後に、pipelineDescriptor オブジェクトを引数として GPUDevice.createRenderPipeline() (en-US) メソッドを呼び出すことで、これに基づいて GPURenderPipeline (en-US) を生成できます。
const renderPipeline = device.createRenderPipeline(pipelineDescriptor);
レンダリングパスの実行
これですべての準備が完了したので、レンダリングパスを実際に実行し、<canvas> への描画を行うことができます。後で GPU に発行するコマンドをエンコードするには、GPUCommandEncoder (en-US) インスタンスを生成する必要があります。これは GPUDevice.createCommandEncoder() (en-US) を呼び出すことで生成できます。
const commandEncoder = device.createCommandEncoder();
次に、GPUCommandEncoder.beginRenderPass() (en-US) を呼び出して GPURenderPassEncoder (en-US) インスタンスを生成することで、レンダリングパスの実行を開始します。このメソッドはディスクリプターオブジェクトを引数にとります。このオブジェクトの唯一の必須プロパティは配列 colorAttachments です。ここでは、以下を指定します。
- レンダリング先のテクスチャービュー:
context.getCurrentTexture().createView()(en-US) により<canvas>から新しいビューを生成します。 - ビューをロード後任意の描画を行う前に指定の色に「クリア」すること。これにより、三角形の後ろの青い背景を生成します。
- 現在のレンダリングパスの値をこのカラーアタッチメント用に格納すること。
const clearColor = { r: 0.0, g: 0.5, b: 1.0, a: 1.0 };
const renderPassDescriptor = {
colorAttachments: [
{
clearValue: clearColor,
loadOp: "clear",
storeOp: "store",
view: context.getCurrentTexture().createView(),
},
],
};
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
すると、三角形を描画するためにレンダリングパスエンコーダーのメソッドを呼び出すことができるようになります。
renderPipelineオブジェクトを引数としてGPURenderPassEncoder.setPipeline()(en-US) を呼び出すことにより、レンダリングパスで使用するパイプラインを指定します。vertexBufferオブジェクトを引数としてGPURenderPassEncoder.setVertexBuffer()(en-US) を呼び出すことにより、レンダリング用にパイプラインに渡すデータソースにします。最初の引数は頂点バッファーを設定するスロットであり、バッファーのレイアウトを記述する配列vertexBuffersの要素のインデックスの参照です。GPURenderPassEncoder.draw()(en-US) により描画を実行します。vertexBufferには 3 個の頂点のデータが格納されているので、それらすべてを描画するために頂点数の値を3に設定します。
passEncoder.setPipeline(renderPipeline);
passEncoder.setVertexBuffer(0, vertexBuffer);
passEncoder.draw(3);
コマンド列のエンコードを完了して GPU に発行するために、あと 3 個の手順が必要です。
GPURenderPassEncoder.end()(en-US) メソッドを呼び出し、レンダーパスコマンドリストの終わりを示します。GPUCommandEncoder.finish()(en-US) メソッドを呼び出し、発行したコマンドの列の記録を完了し、GPUCommandBuffer(en-US) オブジェクトインスタンスにカプセル化します。GPUCommandBuffer(en-US) を GPU に送るため、デバイスの (GPUQueue(en-US) インスタンスで表される) コマンドキューに送信します。デバイスのキューはGPUDevice.queue(en-US) プロパティを通じて利用可能であり、GPUQueue.submit()(en-US) を呼び出すことでキューにGPUCommandBuffer(en-US) のインスタンスの配列を追加できます。
これらの 3 個の手順は以下の 2 行で実現できます。
passEncoder.end();
device.queue.submit([commandEncoder.finish()]);
コンピュートパイプラインの基本
計算基本デモでは、GPU にある値を計算させ、それらを出力バッファーに書き込み、そのデータをステージングバッファーにコピーし、JavaScript からデータを読み取ってコンソールに記録できるようにステージングバッファーをマップします。
このアプリケーションは、レンダリング基本デモに似た構造をなぞります。以前と同様に GPUDevice (en-US) の参照を生成し、GPUDevice.createShaderModule() (en-US) の呼び出しによりシェーダーコードを GPUShaderModule (en-US) にカプセル化します。ここでの違いは、シェーダーコードに @compute ステージという 1 個のシェーダーステージしか無いことです。
// グローバルのバッファサイズを定義する
const BUFFER_SIZE = 1000;
const shader = `
@group(0) @binding(0)
var<storage, read_write> output: array<f32>;
@compute @workgroup_size(64)
fn main(
@builtin(global_invocation_id)
global_id : vec3u,
@builtin(local_invocation_id)
local_id : vec3u,
) {
// バッファーの範囲外にアクセスしないようにする
if (global_id.x >= ${BUFFER_SIZE}) {
return;
}
output[global_id.x] =
f32(global_id.x) * 1000. + f32(local_id.x);
}
`;
データを扱うバッファの生成
この例では、データを扱うために 2 個の GPUBuffer (en-US) インスタンスを生成します。GPU での計算結果を高速で書き込む output バッファーと、output の内容をコピーして JavaScript から値にアクセスできるようにマップできる stagingBuffer です。
outputは、コピー操作のコピー元となるストレージバッファーとして指定されています。stagingBufferは JavaScript から読むためにマップでき、コピー操作のコピー先となるバッファーとして指定されています。
const output = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
const stagingBuffer = device.createBuffer({
size: BUFFER_SIZE,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
});
バインドグループレイアウトの生成
パイプラインの生成時、そのパイプラインで使用するバインドグループを指定します。このためには、まずこのパイプラインで用いるバッファーなどの GPU リソースの構造と目的を定義する GPUBindGroupLayout (en-US) を (GPUDevice.createBindGroupLayout() (en-US) を呼び出すことにより) 生成します。このレイアウトは、バインドグループが従うテンプレートとして用いられます。ここでは、パイプラインがバインディングスロット 0 (シェーダーコードの関連するバインディング番号 @binding(0) に対応します) に結びつき、パイプラインのコンピュートステージで使用でき、バッファーの目的が storage と定義された 1 個のメモリーバッファーにアクセスできるようにします。
const bindGroupLayout = device.createBindGroupLayout({
entries: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
buffer: {
type: "storage",
},
},
],
});
次に、GPUDevice.createBindGroup() (en-US) を呼び出すことにより、GPUBindGroup (en-US) を生成します。このメソッドに、バインドグループのベースとなるバインドグループレイアウトを指定するディスクリプターオブジェクトと、このレイアウトで定義されたスロットにバインドする変数の詳細を渡します。ここでは、バインディング 0 を宣言し、前に定義した output バッファーをそれにバインドするよう指定します。
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [
{
binding: 0,
resource: {
buffer: output,
},
},
],
});
メモ: GPUComputePipeline.getBindGroupLayout() (en-US) メソッドを呼び出すことで、バインドグループの生成時に使用される暗黙のレイアウトを取得できます。さらに、レンダーパイプラインで利用可能なバージョンもあります。GPURenderPipeline.getBindGroupLayout() (en-US) を参照してください。
コンピュートパイプラインの生成
上記すべてを用意したら、パイプラインディスクリプターオブジェクトを渡して GPUDevice.createComputePipeline() (en-US) を呼び出すことで、コンピュートパイプラインを生成できます。これは、レンダーパイプラインの生成と似た方法です。コンピュートシェーダーを記述し、コードを探すモジュールとエントリーポイントを指定します。さらに、パイプラインの layout も指定します。ここでは、GPUDevice.createPipelineLayout() (en-US) を呼び出し、前に定義した bindGroupLayout をベースにレイアウトを生成します。
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout],
}),
compute: {
module: shaderModule,
entryPoint: "main",
},
});
ここでのレンダーパイプラインのレイアウトとの違いの一つは、何も描画を行わないので、プリミティブの種類を指定していないことです。
コンピュートパスの実行
コンピュートパスの実行はレンダリングパスの実行と構造は似ており、別のコマンドを用います。まず、GPUCommandEncoder.beginComputePass() (en-US) によりパスエンコーダーを生成します。
コマンドの発行には、以前と同様に GPUComputePassEncoder.setPipeline() (en-US) を用いてパイプラインを指定します。しかし、その後は、GPUComputePassEncoder.setBindGroup() (en-US) を用いて計算に用いるデータの指定に bindGroup を用いることを指定し、GPUComputePassEncoder.dispatchWorkgroups() (en-US) を用いて計算の実行に用いる GPU ワークグループの数を指定します。
そして、GPURenderPassEncoder.end() (en-US) を用いてレンダーパスのコマンドリストの終端を示します。
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups(Math.ceil(BUFFER_SIZE / 64));
passEncoder.end();
結果を JavaScript で読み取る
GPUQueue.submit() (en-US) を用いてエンコードされたコマンドを実行用に GPU に送信する前に、GPUCommandEncoder.copyBufferToBuffer() (en-US) を用いて output バッファーの中身を stagingBuffer バッファーにコピーします。
// 出力バッファーをステージングバッファーにコピーする
commandEncoder.copyBufferToBuffer(
output,
0, // コピー元のオフセット
stagingBuffer,
0, // コピー先のオフセット
BUFFER_SIZE,
);
// コマンドバッファーの配列を実行用のコマンドキューに渡し、フレームを終える
device.queue.submit([commandEncoder.finish()]);
出力データが stagingBuffer で参照可能になったら、GPUBuffer.mapAsync() (en-US) メソッドを用いてデータを中間メモリーにマップし、GPUBuffer.getMappedRange() (en-US) を用いてマップされた範囲への参照を取得し、データを JavaScript にコピーし、コンソールに記録します。さらに、処理が完了したら stagingBuffer のマップを解除します。
// JS に結果を読み戻すため、ステージングバッファーをマップする
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // オフセット
BUFFER_SIZE, // サイズ
);
const copyArrayBuffer = stagingBuffer.getMappedRange(0, BUFFER_SIZE);
const data = copyArrayBuffer.slice();
stagingBuffer.unmap();
console.log(new Float32Array(data));
GPU エラーの処理
WebGPU の呼び出しは、GPU 処理の中で非同期で検証されます。エラーが検出された場合は、プログラムの呼び出しが GPU 側で無効とマークされます。無効になった呼び出しの返り値に依存する他の呼び出しが行われた場合は、このオブジェクトも無効とマークされ、その先も同様です。このため、WebGPU におけるエラーは「感染性」といわれます。
それぞれの GPUDevice (en-US) のインスタンスは、各自のエラースコープスタックを管理します。このスタックは最初は空で、特定の種類のエラーをキャプチャするため GPUDevice.pushErrorScope() (en-US) を呼び出してスタックにエラースコープをプッシュできます。
エラーのキャプチャが完了したら、GPUDevice.popErrorScope() (en-US) を呼び出すことでキャプチャを終了できます。これは、スタックからスコープをポップし、スコープで最初にキャプチャされたエラーを表現するオブジェクト (GPUInternalError (en-US) または GPUOutOfMemoryError (en-US) または GPUValidationError (en-US)) か、エラーがキャプチャされていない場合は null で解決する Promise を返します。
適する場合は、WebGPU のコードでなぜエラーが発生しているのかを理解する助けとなる有用な情報を「バリデーション」節で提供することを試みました。この節では、エラーを回避するために満たすべき基準を列挙しています。例として、GPUDevice.createBindGroup() のバリデーション節 (en-US)を参照してください。この情報には複雑なものもあります。仕様を繰り返すのではなく、以下の性質を持つエラーの基準のみを列挙することにしました。
- 明らかではないもの。たとえば、バリデーションエラーを発生させるディスクリプタープロパティの組み合わせです。正しいディスクリプターオブジェクトの構造を確実に使うよう言うのは意味がありません。これは明らかであり、あいまいです。
- 開発者が制御できるもの。エラーの基準のいくつかは内部のみに基づき、ウェブ開発者には関係ありません。
explainer で、WebGPU のエラー処理についての詳細情報を得ることができます。Object validity and destroyed-ness および Errors を参照してください。WebGPU Error Handling best practices には有用な実世界での例やアドバイスがあります。
メモ: WebGL でエラーを処理する歴史上の方法は、エラーの情報を返す getError() (en-US) メソッドを提供することです。これはエラーを同期式で返し、効率がよくないという問題があります。これを呼び出すごとに GPU との往復のやりとりを行い、これまで発行した処理がすべて完了するまで待つ必要があります。さらに、状態モデルはフラット、すなわち関係ないコードの間でエラーが漏れる可能性があります。WebGPU の作者はこれらの点を改善することにしました。
インターフェイス
API のエントリーポイント
-
この API のエントリーポイントです。現在のコンテキスト用の
GPUオブジェクトを返します。 GPU-
WebGPU を用いるための出発点です。
GPUAdapterを得るのに用いることができます。 GPUAdapter-
GPU アダプターを表します。これを用いて
GPUDevice(en-US)、アダプターの情報、機能、制限を要求できます。 GPUAdapterInfo-
アダプターについての特定用の情報を保持します。
GPU デバイスの設定
GPUDevice(en-US)-
論理 GPU デバイスを表します。これは WebGPU の機能の大半へのアクセスに用いるメインインターフェイスです。
GPUSupportedFeatures-
GPUAdapterやGPUDevice(en-US) が対応している追加の機能を表す Set 風オブジェクトです。 GPUSupportedLimits-
GPUAdapterやGPUDevice(en-US) が対応している制限を表します。
描画を行う <canvas> の設定
HTMLCanvasElement.getContext()—"webgpu"contextType-
"webgpu"contextTypeを指定してgetContext()を呼び出すと、GPUCanvasContext(en-US) オブジェクトのインスタンスを返します。これは、GPUCanvasContext.configure()(en-US) を用いて設定できます。 GPUCanvasContext(en-US)-
<canvas>要素の WebGPU レンダリングコンテキストを表します。
パイプラインリソースの表現
GPUBuffer(en-US)-
GPU での処理で用いる生データを格納できるメモリーのブロックを表します。
GPUExternalTexture(en-US)-
GPU でのレンダリング処理でテクスチャーとして用いることができる
HTMLVideoElementのスナップショットが格納されたラッパーオブジェクトです。 GPUSampler(en-US)-
シェーダーがテクスチャーのリソースデータの変換やフィルターを行う方法を制御します。
GPUShaderModule(en-US)-
内部のシェーダーモジュールオブジェクトへの参照で、パイプラインにより実行用に GPU に送信できる WGSL のシェーダーコードのコンテナーです。
GPUTexture(en-US)-
GPU でのレンダリング処理で使用する用の、画像などの 1 次元、2 次元、または 3 次元のデータの配列を格納するのに用いるコンテナーです。
GPUTextureView(en-US)-
特定の
GPUTexture(en-US) で定義された、テクスチャーのサブリソースの部分のビューです。
パイプラインの表現
GPUBindGroup(en-US)-
GPUBindGroupLayout(en-US) に基づき、GPUBindGroupはグループで一緒にバインドされるリソースの集合と、これらのリソースのシェーダーステージでの利用法を定義します。 GPUBindGroupLayout(en-US)-
パイプラインで用いられるバッファーなどの関連する GPU リソースの構造と目的を定義し、
GPUBindGroup(en-US) を生成する際のテンプレートとして用いられます。 GPUComputePipeline(en-US)-
コンピュートシェーダーステージを制御し、
GPUComputePassEncoder(en-US) で使用できます。 GPUPipelineLayout(en-US)-
パイプラインで用いる
GPUBindGroupLayout(en-US) を定義します。コマンドのエンコード時にパイプラインとともに用いるGPUBindGroup(en-US) は、互換性があるGPUBindGroupLayout(en-US) を持っている必要があります。 GPURenderPipeline(en-US)-
バーテックスシェーダーステージとフラグメントシェーダーステージを制御し、
GPURenderPassEncoder(en-US) やGPURenderBundleEncoder(en-US) で使用できます。
コマンドのエンコードと GPU への送信
GPUCommandBuffer(en-US)-
実行用に
GPUQueue(en-US) に送信できる、記録した GPU コマンドのリストを表します。 GPUCommandEncoder(en-US)-
コマンドエンコーダーを表します。GPU に発行するコマンドのエンコードに使用します。
GPUComputePassEncoder(en-US)-
GPUComputePipeline(en-US) が発行し、コンピュートシェーダーステージの制御に関するコマンドをエンコードします。GPUCommandEncoder(en-US) による全体のエンコード処理の一部です。 GPUQueue(en-US)-
GPU でのエンコードされたコマンドの実行を制御します。
GPURenderBundle(en-US)-
事前に記録されたコマンド群のバンドル用のコンテナーです。(
GPURenderBundleEncoder(en-US) を参照してください) GPURenderBundleEncoder(en-US)-
コマンド群のバンドルを事前に記録するのに使用します。これらは、必要に応じて何度でも、
executeBundles()(en-US) メソッドによりGPURenderPassEncoder(en-US) で再利用できます。 GPURenderPassEncoder(en-US)-
GPURenderPipeline(en-US) が発行し、バーテックスシェーダーステージとフラグメントシェーダーステージの制御に関するコマンドをエンコードします。GPUCommandEncoder(en-US) による全体のエンコード処理の一部です。
レンダリングパスにおけるクエリーの実行
GPUQuerySet(en-US)-
オクルージョンやタイムスタンプのクエリーなど、パスにおけるクエリーの結果の記録に用います。
エラーのデバッグ
GPUCompilationInfo(en-US)-
GPUCompilationMessage(en-US) オブジェクトの配列です。シェーダーコードの問題の診断を助けるため、GPU シェーダーモジュールコンパイラーにより生成されます。 GPUCompilationMessage(en-US)-
GPU シェーダーモジュールコンパイラーが生成した、1 個の情報、警告、もしくはエラーのメッセージを表します。
GPUDeviceLostInfo(en-US)-
GPUDevice.lost(en-US)Promiseが解決する際に返され、デバイスがロストした原因の情報を提供します。 GPUError(en-US)-
GPUDevice.popErrorScope(en-US) およびuncapturederror(en-US) イベントで浮かび上がったエラー用のベースインターフェイスです。 GPUInternalError(en-US)-
GPUDevice.popErrorScope(en-US) およびGPUDevice(en-US)uncapturederror(en-US) イベントで浮かび上がったエラーの型の一つです。バリデーションの要求がすべて満たされたにもかかわらずシステムまたは実装に固有の理由で処理に失敗したことを表します。 GPUOutOfMemoryError(en-US)-
GPUDevice.popErrorScope(en-US) およびGPUDevice(en-US)uncapturederror(en-US) イベントで浮かび上がったエラーの型の一つです。要求された処理を完了するのに十分な空きメモリが無かったことを表します。 GPUPipelineError(en-US)-
パイプラインの失敗を表現します。この値は
GPUDevice.createComputePipelineAsync()(en-US) やGPUDevice.createRenderPipelineAsync()(en-US) から返されたPromiseが拒否されたとき渡されます。 GPUUncapturedErrorEvent(en-US)-
GPUDevice(en-US)uncapturederror(en-US) イベント用のイベントオブジェクトの型です。 GPUValidationError(en-US)-
GPUDevice.popErrorScope(en-US) およびGPUDevice(en-US)uncapturederror(en-US) イベントで浮かび上がったエラーの型の一つです。操作が WebGPU API のバリデーションの制約を満たさなかったことを表すアプリケーションエラーを表現します。
セキュリティの要件
この API 全体は安全なコンテキストでのみ利用可能です。
例
仕様書
| Specification |
|---|
| WebGPU # gpu-interface |
ブラウザーの互換性
BCD tables only load in the browser