ストリーム API の概念
ストリーム API は、とても便利なツールセットをウェブプラットフォームに追加し、 JavaScript がネットワーク経由で受信したデータのストリームにプログラムからアクセスし、開発者の希望どおりに処理できるようにするオブジェクトを提供します。ストリームに関連する概念や用語の中には、初めて耳にするものもあるかもしれません。この記事では、知るべきことをすべて説明しています。
読み取り可能なストリーム
読み取り可能なストリームは、基になるソース (underlying source) から流れる ReadableStream オブジェクトによって JavaScript で表されるデータソースです。 基になるソースは、ネットワーク上のどこか、またはデータを取得するドメインのどこかにあるリソースです。
基になるソースには、次の 2 種類があります。
- プッシュソース (Push sources) は、アクセスしたときに常にデータをプッシュします。 ストリームへのアクセスを開始、一時停止、またはキャンセルするのはユーザー次第です。 例には、動画ストリームや TCP/ウェブソケットが含まれます。
- プルソース (Pull sources) では、接続後、明示的にデータを要求する必要があります。 例には、Fetch や XHR の呼び出しを介したファイルアクセス操作が含まれます。
データは、チャンク (chunks) と呼ばれる小さな断片で順番に読み取られます。 チャンクは 1 バイトにすることも、特定のサイズの型付き配列など、より大きなものにすることもできます。 単一のストリームには、さまざまなサイズとタイプのチャンクを含めることができます。
ストリームに置かれたチャンクは、キューに入った (enqueued) と言われます。 これは、読み取りの準備ができているキューで待機していることを意味します。 内部キュー(internal queue)は、まだ読み取られていないチャンクを追跡します(下の内部キューとキューイング戦略のセクションを参照)。
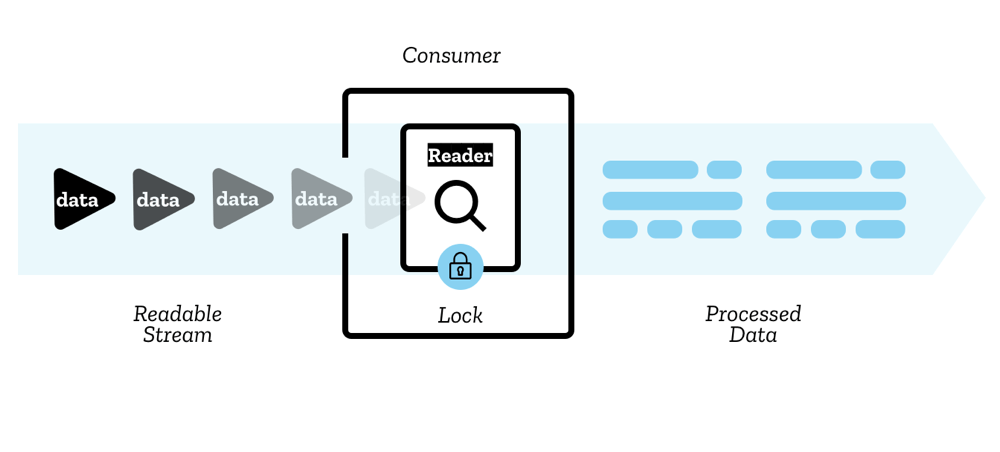
ストリーム内のチャンクはリーダー (reader) によって読み取られます。 これにより、一度に 1 つのチャンクでデータが処理されるため、ユーザーは任意の種類の操作を実行できます。 リーダーとそれに付随する他の処理コードは、コンシューマー (consumer) と呼ばれます。
また、コントローラー (controller) と呼ばれる構造も使用します。 各リーダーには、ストリームを制御する(例えば、必要に応じてキャンセルする)ことができるコントローラーが関連付けられています 。
一度にストリームを読み取ることができるのは 1 つのリーダーのみです。 リーダーが作成され、ストリームの読み取りを開始すると、ストリームはアクティブなリーダー (active reader) にロックされている (locked) と言います。 別のリーダーにストリームの読み取りを開始させる場合は、通常、最初のリーダーをキャンセルしてから他の操作を行う必要があります(ですが、ストリームを分岐 (tee) することができます。下の分岐の節を参照)。
読み取り可能なストリームには 2 つの異なる種類があることに注意してください。 従来の読み取り可能なストリームに加えて、バイトストリームと呼ばれる種類があります。 これは、基になるバイトソース(BYOB または bring your own buffer(独自のバッファーを持ち込む)とも呼ばれる)のソースを読み取るための従来のストリームの拡張バージョンです。 これにより、開発者が提供するバッファーにストリームを直接読み込むことができ、必要なコピーが最小限に抑えられます。 コードが使用する基になるストリーム(そして拡張により、リーダーとコントローラー)は、最初にストリームがどのように作成されたかによって異なります(ReadableStream() コンストラクターのページを参照)。
フェッチリクエストからの Response.body などのメカニズムを介して既製の読み取り可能なストリームを使用するか、ReadableStream() コンストラクターを使用して独自のストリームを使用できます。
分岐
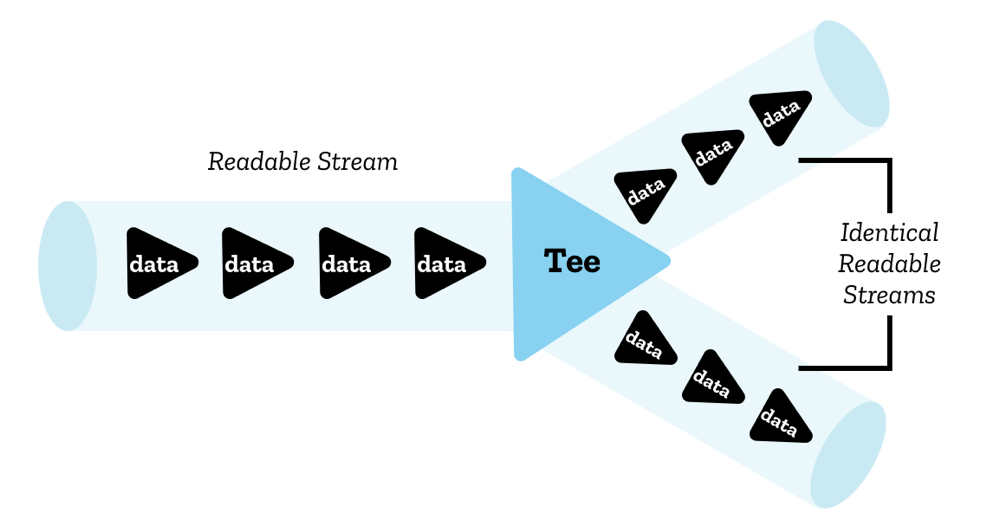
一度にストリームを読み取ることができるのは 1 つのリーダーだけですが、ストリームを 2 つの同一のコピーに分割し、2 つの別々のリーダーで読み取ることができます。 これを分岐 (teeing) と呼びます。
JavaScript では、これを ReadableStream.tee() メソッドを介して実現します。元の読み取り可能なストリームの 2 つの同一コピーを含む配列を出力し、2 つの別々のリーダーで個別に読み取ることができます。
例えば、サーバーからレスポンスを取得してブラウザーにストリーミングしたいが、サービスワーカーのキャッシュにもストリームしたい場合に、サービスワーカーでこれを行うことができます。 レスポンスの本体を複数回使用することはできず、ストリームを一度に複数のリーダーで読み取ることはできないため、これを行うには 2 つのコピーが必要です。
書き込み可能なストリーム
書き込み可能なストリーム (writable stream) は、WritableStream オブジェクトによって JavaScript で表されるデータの書き込み先です。 これは、基になるシンク(underlying sink、生データが書き込まれる下位レベルの I/O シンク)の上部の抽象化として機能します。
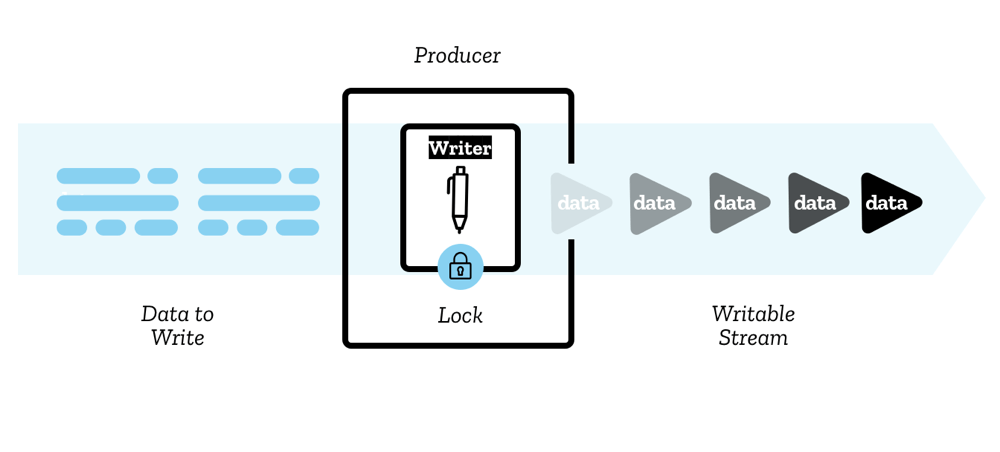
データは、ライター (writer) を介して一度に 1 つのチャンクでストリームに書き込まれます。 チャンクは、リーダーのチャンクと同様に、多数の形式をとることができます。 任意のコードを使用して、書き込み可能なチャンクを生成できます。 ライターとそれに関連するコードをプロデューサー (producer) と呼びます。
ライターが作成され、ストリームへの書き込みを開始すると、ストリームはアクティブなライター (active writer) にロックされている (locked) と言われます。 一度に書き込み可能なストリームに書き込むことができるのは、1 つのライターのみです。 別のライターにストリームへの書き込みを開始させたい場合は、通常、別のライターを取りつける前にそれを中止する必要があります。
内部キュー (internal queue) は、ストリームに書き込まれたが、基になるシンクによってまだ処理されていないチャンクを追跡します。
また、コントローラーと呼ばれる構造も使用します。 各ライターには、ストリームを制御する(例えば、必要に応じてストリームを中止する)ことができるコントローラーが関連付けられています 。
WritableStream() コンストラクターを使用して、書き込み可能なストリームを利用できます。 現在、これらのブラウザーでの可用性は非常に限られています。
パイプチェーン
ストリーム API では、パイプチェーン (pipe chain) と呼ばれる構造を使用して、ストリームを互いにパイプ接続することが可能です。
-
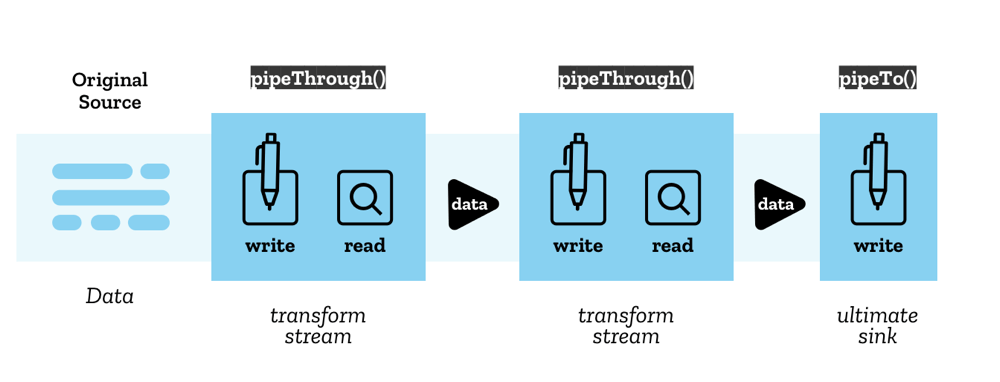
ReadableStream.pipeThrough()- ストリームを変換ストリーム (transform stream) に通してパイプ接続し、途中でデータ形式を変換することができます。 これは、例えば、動画フレームのエンコードやデコード、データの圧縮や解凍、ある形式から別の形式へのデータ変換に使用することができます。 変換ストリームは、データが読み込まれる読み取り可能なストリームと、データが書き込まれる書き込み可能なストリームのペアと、データが書き込まれると同時に新しいデータが読み込めるようになることを保証する適切なメカニズムで構成されています。TransformStreamは変換ストリームの具体的な実装ですが、pipeThrough()には、同じ読み取り可能なストリームと書き込み可能なストリームのプロパティを持つ任意のオブジェクトを通すことができます。 ReadableStream.pipeTo()— パイプチェーンの終点として機能する書き込み可能なストリームにパイプ接続します。
パイプチェーンの始まりは元のソース (original source) と呼ばれ、終わりは最終的なシンク (ultimate sink) と呼ばれます。
背圧
ストリームの重要な概念の一つが背圧 (backpressure) です。 これは、単一のストリームまたはパイプチェーンが読み取り/書き込みの速度を調整するプロセスです。 チェーンの後半のストリームがまだビジーで、さらに多くのチャンクを受け入れる準備ができていない場合、チェーンを介して信号を逆方向に送信して、より前の変換ストリーム(または元のソース)に必要に応じて配信速度を落とすよう指示し、どこもボトルネックにならないようにします。
ReadableStream で背圧を使用するには、コントローラーの ReadableStreamDefaultController.desiredSize プロパティを照会することで、コンシューマーが希望するチャンクサイズをコントローラーに問い合わせます。 それが低すぎる場合、ReadableStream は、基になるソースにデータの送信を停止するように指示でき、ストリームチェーンに沿って背圧をかけます。
後でコンシューマーが再びデータを受信したい場合は、ストリームの作成で pull メソッドを使用して、データをストリームに与えるよう基になるソースに指示できます。
内部キューとキューイング戦略
前に述べたように、まだ処理されて終了していないストリーム内のチャンクは、内部キューによって追跡されます。
- 読み取り可能なストリームの場合、これらはキューに入れられたがまだ読み取られていないチャンクです。
- 書き込み可能なストリームの場合、これらは書き込まれたが、基になるシンクによってまだ処理されていないチャンクです。
内部キューは、内部キューの状態(internal queue state) に基づいて背圧を通知する方法を決定するキューイング戦略 (queuing strategy) を採用しています。
一般に、この戦略はキュー内のチャンクのサイズを、キューが管理しやすい最大のチャンクの合計サイズである最高水準点 (high water mark) と呼ばれる値と比較します。
実行される計算は次です。
最高水準点 - キュー内のチャンクの合計サイズ = 希望サイズ
希望サイズ (desired size) は、ストリームが流れ続けるために受け入れることができるチャンクの数ですが、サイズは最高水準未満となります。 チャンクの生成は適宜減速/加速され、希望サイズをゼロ以上に保ちつつ、ストリームを使用可能な限り速く流すことができます。 この値がゼロ(または未満)になった場合、ストリームが対処できる速度よりも速くチャンクが生成されていることを意味しており、問題が発生する可能性があります。
例として、1 のチャンクサイズと 3 の最高水準点を考えてみましょう。 これは、最高水準点に到達して背圧が適用される前に、最大 3 つのチャンクをキューに入れることができることを意味します。