Django 教程 6: 通用列表和详细信息视图
本教程扩充了 LocalLibrary 网站,为书本与作者增加列表与细节页面。此处我们将学到通用类别视图,并演示如何降低你必须为一般使用案例撰写的程式码数量。我们也会更加深入 URL 处理细节,演示如何实施基本模式匹配。
| 前提: | 完成所有先前的教程主题,包含Django 教程 5: 创建主页。 |
|---|---|
| 目标: | 了解如何使用、在何处使用通用类别视图,以及如何从 URLs 取出模式,如何传送资料到视图。 |
概览
本教程中,通过为书本和作者添加列表和详细信息页面,我们将完成第一个版本的LocalLibrary 网站(或者更准确地说,我们将向你展示如何实现书页,并让你自己创建作者页面!)
该过程类似于创建索引页面,我们在上一个教程中展示了该页面。我们仍然需要创建 URL 地图,视图和模板。主要区别在于,对于详细信息页面,我们还有一个额外的挑战,即从 URL 中的模式中提取信息,并将其传递给视图。对于这些页面,我们将演示一种完全不同的视图类型:基于类别的通用列表和详细视图。这些可以显着减少所需的视图代码量,使其更易于编写和维护。
本教程的最后一部分,将演示在使用基于类别的通用列表视图时,如何对数据进行分页。
书本清单页面
书本清单页面,将显示页面中所有可用图书记录的列表,使用 url: catalog/books/ 进行访问。该页面将显示每条记录的标题和作者,标题是指向相关图书详细信息页面的超链接。该页面将具有与站点中,所有其他页面相同的结构和导航,因此,我们可以扩展在上一个教程中创建的基本模板(base_generic.html)。
URL 映射
打开 /catalog/urls.py ,并复制到下面粗体显示的行中。就像索引页面的方式,这个 path() 函数,定义了一个与 URL 匹配的模式('books/'),如果 URL 匹配,将调用视图函数(views.BookListView.as_view())和一个对应这个特定映射的名称。
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
]
正如前一个教程中所讨论的,URL 必须已经先匹配了/catalog,因此实际上将为 URL 调用的视图是:/catalog/books/。
视图函数具有与以前不同的格式 - 这是因为该视图,实际上将以类别来实现。我们将继承现有的泛型视图函数,该函数已经完成了我们希望此视图函数执行的大部分工作,而不是从头开始编写自己的函数。对于基于 Django 类的视图,我们通过调用类方法as_view(),来访问适当的视图函数。这样做可以创建类的实例,并确保为传入的 HTTP 请求调用正确的处理程序方法。
视图 (基于类别)
我们可以很容易地,将书本列表视图编写为常规函数(就像我们之前的索引视图一样),它将查询数据库中的所有书本,然后调用render(),将列表传递给指定的模板。然而,我们用另一种方法取代,我们将使用基于类的通用列表视图(ListView) - 一个继承自现有视图的类。因为通用视图,已经实现了我们需要的大部分功能,并且遵循 Django 最佳实践,我们将能够创建更强大的列表视图,代码更少,重复次数更少,最终维护更少。
打开 catalog/views.py,并将以下代码复制到文件的底部:
from django.views import generic
class BookListView(generic.ListView):
model = Book
就是这样!通用视图将查询数据库,以获取指定模型(Book)的所有记录,然后呈现位于 /locallibrary/catalog/templates/catalog/book_list.html 的模板(我们将在下面创建)。在模板中,你可以使用名为object_list 或 book_list的模板变量(即通常为“the_model_name_list”),以访问书本列表。
备注: 模板位置的这个尴尬路径不是印刷错误 - 通用视图在应用程序的/application_name/templates/目录中(/catalog/templates/),查找模板/application_name/the_model_name_list.html(在本例中为catalog/book_list.html)。
你可以添加属性,以更改上面的默认行为。例如,如果需要使用同一模型的多个视图,则可以指定另一个模板文件,或者如果book_list对于特定模板用例不直观,则可能需要使用不同的模板变量名称。可能最有用的变更,是更改/过滤返回的结果子集 - 因此,你可能会列出其他用户阅读的前 5 本书,而不是列出所有书本。
class BookListView(generic.ListView):
model = Book
context_object_name = 'my_book_list' # your own name for the list as a template variable
queryset = Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
template_name = 'books/my_arbitrary_template_name_list.html' # Specify your own template name/location
覆盖基于类别的视图中的方法
虽然我们不需要在这里执行此操作,但你也可以覆盖某些类别方法。
例如,我们可以覆盖get_queryset()方法,来更改返回的记录列表。这比仅仅设置queryset属性更灵活,就像我们在前面的代码片段中所做的那样(尽管在这种情况下没有真正的好处):
class BookListView(generic.ListView):
model = Book
def get_queryset(self):
return Book.objects.filter(title__icontains='war')[:5] # Get 5 books containing the title war
我们还可以覆盖get_context_data() ,以将其他上下文变量传递给模板(例如,默认情况下传递书本列表)。下面的片段,显示了如何将一个名为“some_data”的变量添加到上下文中(然后它将作为一个模板变量,而被提供)。
class BookListView(generic.ListView):
model = Book
def get_context_data(self, **kwargs):
# Call the base implementation first to get the context
context = super(BookListView, self).get_context_data(**kwargs)
# Create any data and add it to the context
context['some_data'] = 'This is just some data'
return context
这样做时,遵循上面使用的模式非常重要:
- 首先从我们的超类别中,获取现有的上下文。
- 然后添加新的上下文信息。
- 然后返回新的(更新的)上下文。
备注: 查看内置的基于类的通用视图(Django 文档),了解更多可以执行的操作示例。
创建列表视图模板
创建 HTML 文件 /locallibrary/catalog/templates/catalog/book_list.html,并复制到下面的文本中。如上所述,这是基于类的通用列表视图,所期望的默认模板文件(对于名为catalog的应用程序中,名为Book的模型)。
通用视图的模板就像任何其他模板一样(当然,传递给模板的上下文/信息可能不同)。与我们的索引模板一样,我们在第一行扩展基本模板,然后替换名为content的区块。
{% extends "base_generic.html" %}
{% block content %}
<h1>Book List</h1>
{% if book_list %}
<ul>
{% for book in book_list %}
<li>
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
</li>
{% endfor %}
</ul>
{% else %}
<p>There are no books in the library.</p>
{% endif %}
{% endblock %}
视图默认将上下文(书本列表)作为 object_list 和 book_list 的别名传递;任何一个都会奏效。
条件执行
我们使用 if, else 和 endif模板标签,来检查 book_list是否已定义且不为空。如果 book_list为空,则 else子句显示文本,说明没有要列出的书本。如果 book_list不为空,那么我们遍历书本列表。
{% if book_list %}
<!-- code here to list the books -->
{% else %}
<p>There are no books in the library.</p>
{% endif %}
上述条件仅检查一种情况,但你可以使用 elif 模板标记(例如{% elif var2 %} )测试其他条件。有关条件运算符的更多信息,请参阅:if, ifequal/ifnotequal,以及内置模板标记和过滤器(Django Docs)中的 ifchanged 。
For 循环/回圈
模板使用for 和 endfor模板标签,以循环遍历书本列表,如下所示。每次迭代都会使用当前列表项的信息,填充书本模板变量book。
{% for book in book_list %}
<li><!-- code here get information from each book item --></li>
{% endfor %}
虽然这里没有使用,但在循环中,Django 还会创建其他可用于跟踪迭代的变量。例如,你可以测试forloop.last 变量,以运行最后一次循环当中的条件处理代码。
访问变量
循环内的代码,为每本书创建一个列表项,显示作者和标题(作为尚未创建的详细视图的链接)。
<a href="{{ book.get_absolute_url }}">{{ book.title }}</a> ({{book.author}})
我们使用“点符号”(例如 book.title 和 book.author)访问相关书本记录的字段,其中书本项目book后面的文本是字段名称(如同在模型中定义的)。
我们还可以在模板中,调用模型中的函数 - 在这里,我们调用Book.get_absolute_url(),来获取可用于显示关联详细记录的 URL。这项工作提供的函数没有任何参数(没有办法传递参数!)
备注: 在模板中调用函数时,我们必须要小心“副作用”。在这里我们只需要显示一个 URL,但是一个函数几乎可以做任何事情 - 我们不想仅仅通过渲染模板,而删除了我们的数据库(例如)!
更新基本模板
打开基本模板(/locallibrary/catalog/templates/base_generic.html)并将 {% url 'books' %} 插入所有书本 All books 的 URL 链接,如下所示。这将启用所有页面中的链接(由于我们已经创建了“books”的 url 映射器,我们可以成功地将其设置到位)。
<li><a href="{% url 'index' %}">Home</a></li>
<li><a href="{% url 'books' %}">All books</a></li>
<li><a href="">All authors</a></li>
它看起来是什么样子?
你将无法构建书本清单,因为我们仍然缺少依赖项 - 书本详细信息页面的 URL 地图,这是创建单个书本的超链接所必需的。我们将在下一节之后,说明列表和详细视图的部分。
书本详细信息页面
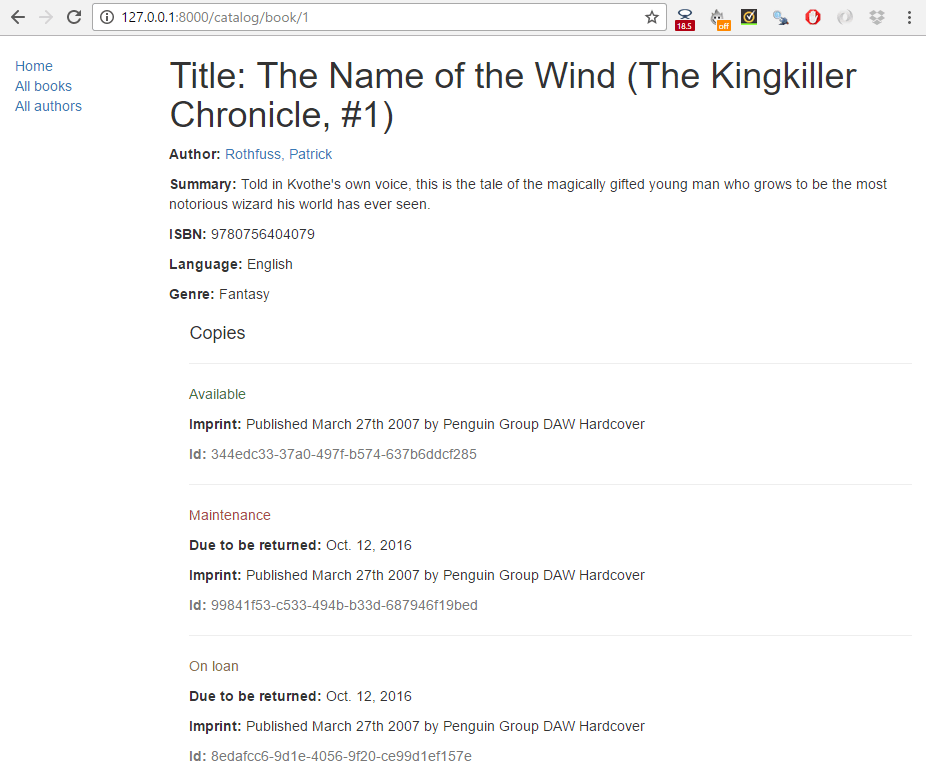
书本详细信息页面,将显示有关特定书本的信息,使用 URL catalog/book/<id>(其中 <id> 是书本的主键)进行访问。除了Book模型中的字段(作者,摘要,ISBN,语言和种类)之外,我们还将列出可用副本(BookInstances)的详细信息,包括状态,预期返回日期,印记和 id。这将使我们的读者,不仅可以了解该书,还可以确认是否/何时可用。
URL 映射
打开 /catalog/urls.py ,并添加下面粗体显示的 “book-detail” URL 映射器。这个 path() 函数定义了一个模式,关联到基于通用类的详细信息视图和名称。
urlpatterns = [
path('', views.index, name='index'),
path('books/', views.BookListView.as_view(), name='books'),
path('book/<int:pk>', views.BookDetailView.as_view(), name='book-detail'),
]
对于书本详细信息路径,URL 模式使用特殊语法,来捕获我们想要查看的书本的特定 id。语法非常简单:尖括号定义要捕获的 URL 部分,包含视图可用于访问捕获数据的变量的名称。例如,<something> 将捕获标记的模式,并将值作为变量“something” ,传递给视图。你可以选择在变量名称前,加上一个定义数据类型的转换器规范(int,str,slug,uuid,path)。
在这里,我们使用 '<int:pk>' 来捕获 book id,它必须是一个整数,并将其作为名为 pk 的参数(主键的缩写)传递给视图。
备注: 如前所述,我们匹配的 URL 实际上是 catalog/book/<digits>(因为我们在应用程序 catalog 中,假定使用/catalog/)。
警告: 基于类的通用详细信息视图,需要传递一个名为 pk 的参数。如果你正在编写自己的函数视图,则可以使用你喜欢的任何参数名称,或者,确实也可以,在未命名的参数中传递信息。
高级路径匹配/正则表达式入门
备注: 完成教程并不需要此部分说明!我们提供它,是因为了解此可选的部分,未来可能对你使用 Django 有帮助。
path()提供的模式匹配非常简单,对于你只想捕获任何字符串或整数的(非常常见的)情况非常有用。如果需要更精细的过滤(例如,仅过滤具有一定数量字符的字符串),则可以使用 re_path() 方法。
此方法与
path()的使用一样,除了它允许你使用正则表达式,以指定模式。例如,上面的路径可以编写为如下所示:
re_path(r'^book/(?P<pk>\d+)$', views.BookDetailView.as_view(), name='book-detail'),
正则表达式是一种非常强大的模式映射工具。坦率地说,对于初学者来说,他们是非常不直观和可怕的。下面是一个非常短的入门!
首先要知道的是,正则表达式通常应该使用原始字符串文字语法声明(即它们如图所示:r'<你的正则表达式文本放在这里>')。
声明模式匹配需要知道的语法,主要部分是:
| 符号 | 含义 |
|---|---|
| ^ | 匹配文本的开头 |
| $ | 匹配文本的结尾 |
| \d | 匹配一个位数的数字(0,1,2,... 9) |
| \w |
匹配单词字符,例如字母,数字或下划线字符(_)中的任何大写或小写字符 |
| + |
匹配前面一个或多个字符。例如,要匹配一个或多个位数的数字,你将使用\d+。要匹配一个或多个“a”字符,你可以使用
a+
|
| * | 匹配前面字符的零个或多个。例如,要匹配没有内容或单词,你可以使用\w* |
| ( ) | 捕获括号内部模式的一部分。任何捕获的值,都将作为未命名参数,传递给视图(如果捕获了多个模式,则将按照声明捕获的顺序,提供相关参数)。 |
| (?P<name>...) | 捕获模式(由...表示)作为命名变量(在本例中为“name”)。捕获的值,将传递给具有指定名称的视图。因此,你的视图,必须声明具有相同名称的参数! |
| [ ] | 匹配集合中的一个字符。例如,[abc] 将匹配 'a' 或 'b' 或 'c'。 [-\w] 将匹配 ' - ' 字符,或任何单词字符。 |
大多数其他字符可以按字面意思理解!
让我们考虑一些模式的真实例子:
| 模式 | 描述 |
|---|---|
| r'^book/(?P<pk>\d+)$' |
这是我们的 url 映射器中使用的
RE。它匹配一个字符串,该字符串在行(^book/)的开头具有 它还捕获所有数字(?P<pk>\d+),并将它们传递给名为 'pk' 的参数中的视图。捕获的值始终作为字符串传递!
例如,这将匹配 |
| r'^book/(\d+)$' | 这与前面的例子匹配相同的 URL。捕获的信息,将作为未命名的参数,发送到视图。 |
| r'^book/(?P<stub>[-\w]+)$' |
这匹配一个字符串,该字符串在行(^book/)的开头具有
这是“stub”的一种相当典型的模式。存根 stub 是用于数据的、URL
友好的、基于单词的主键。如果你希望本书网址提供更多信息,则可以使用
stub。例如
|
你可以在一个匹配中捕获多个模式,从而在 URL 中,编码许多不同的信息。
备注: 作为一项挑战,请考虑如何对网址进行编码,以列出特定年份,月份,日期的所有图书,以及可用于匹配它的规则表达式 RE。
在 URL 地图中传递其他选项
我们在这里没有使用、但你可能觉得有价值的一个功能是,你可以向视图声明并传递其他选项。这些选项被声明为一个字典,你将其作为第三个未命名参数,传递给 path()函数。
如果要对多个资源,使用相同的视图,并在每种情况下,传递数据以配置其行为,则此方法非常有用(下面我们在每种情况下提供不同的模板)。
path('url/', views.my_reused_view, {'my_template_name': 'some_path'}, name='aurl'),
path('anotherurl/', views.my_reused_view, {'my_template_name': 'another_path'}, name='anotherurl'),
备注: 额外选项和命名捕获的模式,二者都作为命名参数传递给视图。如果对捕获的模式和额外选项使用相同的名称,则仅将捕获的模式值发送到视图(将删除附加选项中指定的值)。
视图 (基于类别)
打开 catalog / views.py,并将以下代码复制到文件的底部:
class BookDetailView(generic.DetailView):
model = Book
就是这样!你现在需要做的就是创建一个名为 /locallibrary/catalog/templates/catalog/book_detail.html 的模板,该视图将向此模板,传递 URL 映射器提取的特定 Book 记录的数据库信息。在模板中,你可以使用名为 object 或 book的模板变量(即通常为“the_model_name”),以访问书本列表。
如果需要,可以更改使用的模板,以及用于在模板中,引用该书本的上下文对象的名称。你还可以覆盖方法,例如,向上下文添加其他信息。
如果记录不存在会怎样?
如果请求的记录不存在,那么基于类的通用详细信息视图,将自动为你引发 Http404 异常 - 在生产环境中,这将自动显示适当的“未找到资源”页面,你可以根据需要自定义该页面。
为了让你了解其工作原理,下面的代码片段,演示了如何在不使用基于类的详细信息视图的情况下,将基于类的视图实现为函数。
def book_detail_view(request,pk):
try:
book_id=Book.objects.get(pk=pk)
except Book.DoesNotExist:
raise Http404("Book does not exist")
#book_id=get_object_or_404(Book, pk=pk)
return render(
request,
'catalog/book_detail.html',
context={'book':book_id,}
)
视图首先尝试从模型中,获取特定的书本记录。如果失败,则视图应引发 Http404异常,以指示该书本“未找到”。然后,最后一步是使用模板名称,和上下文参数context中的书本数据(作为字典)调用render()。
备注: get_object_or_404()(如上所示)是一个方便的快捷方式,用于在未找到记录时,引发 Http404 异常。
创建详细信息视图模板
创建 HTML 文件 /locallibrary/catalog/templates/catalog/book_detail.html,并为其提供以下内容。如上所述,这是基于类的通用详细信息视图,所期望的默认模板文件名(对于名为 catalog 的应用程序中名为 Book 的模型)。
{% extends "base_generic.html" %}
{% block content %}
<h1>Title: {{ book.title }}</h1>
<p><strong>Author:</strong> <a href="">{{ book.author }}</a></p> <!-- author detail link not yet defined -->
<p><strong>Summary:</strong> {{ book.summary }}</p>
<p><strong>ISBN:</strong> {{ book.isbn }}</p>
<p><strong>Language:</strong> {{ book.language }}</p>
<p><strong>Genre:</strong> {% for genre in book.genre.all %} {{ genre }}{% if not forloop.last %}, {% endif %}{% endfor %}</p>
<div style="margin-left:20px;margin-top:20px">
<h4>Copies</h4>
{% for copy in book.bookinstance_set.all %}
<hr>
<p class="{% if copy.status == 'a' %}text-success{% elif copy.status == 'm' %}text-danger{% else %}text-warning{% endif %}">{{ copy.get_status_display }}</p>
{% if copy.status != 'a' %}<p><strong>Due to be returned:</strong> {{copy.due_back}}</p>{% endif %}
<p><strong>Imprint:</strong> {{copy.imprint}}</p>
<p class="text-muted"><strong>Id:</strong> {{copy.id}}</p>
{% endfor %}
</div>
{% endblock %}
备注: 上面模板中的作者链接,有一个空 URL,因为我们尚未创建作者详细信息页面。一旦创建了,你应该像这样更新 URL:
<a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a>
虽然有点大,但此模板中的几乎所有内容,都已在前面描述过:
- 我们扩展基本模板,并覆盖“内容”区块 content。
- 我们使用条件处理,来确定是否显示特定内容。
- 我们使用
for循环遍历对象列表。 - 我们使用 "点表示法" 访问上下文字段(因为我们使用了详细的通用视图,上下文被命名为
book;我们也可以使用“object”)。
我们以前没见过的一件有趣的事情是函数book.bookinstance_set.all()。此方法由 Django“自动”构造,以便返回与特定 Book 相关联的 BookInstance记录集合。
{% for copy in book.bookinstance_set.all %}
<!-- code to iterate across each copy/instance of a book -->
{% endfor %}
需要此方法,是因为你仅在关系的“一”侧声明 ForeignKey(一对多)字段。由于你没有做任何事情,来声明其他(“多”)模型中的关系,因此它没有任何字段,来获取相关记录集。为了解决这个问题,Django 构造了一个适当命名的“反向查找”函数,你可以使用它。函数的名称,是通过对声明 ForeignKey 的模型名称,转化为小写来构造的,然后是_set(即,在 Book中创建的函数是 bookinstance_set())。
备注: 这里我们使用all()来获取所有记录(默认值)。虽然你可以使用filter()方法获取代码中的记录子集,但你无法直接在模板中执行此操作,因为你无法指定函数的参数。
还要注意,如果你没有定义顺序(在基于类的视图或模型上),你还会看到开发服务器中的错误,如下所示:
[29/May/2017 18:37:53] "GET /catalog/books/?page=1 HTTP/1.1" 200 1637 /foo/local_library/venv/lib/python3.5/site-packages/django/views/generic/list.py:99: UnorderedObjectListWarning: Pagination may yield inconsistent results with an unordered object_list: <QuerySet [<Author: Ortiz, David>, <Author: H. McRaven, William>, <Author: Leigh, Melinda>]> allow_empty_first_page=allow_empty_first_page, **kwargs)
发生这种情况,是因为 paginator object 对象希望在下划线数据库上看到一些 ORDER BY。没有它,它无法确定,返回的注册表实际上是否为正确顺序!
本教程还没有说明到 Pagination(还没,但很快),但由于你不能使用sort_by() 并传递一个参数(与上面描述的filter() 相同),你将不得不在下面三个选择当中,进行挑选:
- 在模型的
class Meta声明中,添加排序ordering。 - Add a
querysetattribute in your custom class-based view, specifying aorder_by().在自定义基于类的视图中添加 queryset 属性,指定 order_by()。 - Adding a
get_querysetmethod to your custom class-based view and also specify theorder_by().将 get_queryset 方法添加到基于类的自定义视图中,并指定 order_by()。
如果你决定使用class Meta 作为作者模型Author(可能不像定制基于类的视图那样灵活,但很容易),你最终会得到这样的结果:
class Author(models.Model):
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
date_of_birth = models.DateField(null=True, blank=True)
date_of_death = models.DateField('Died', null=True, blank=True)
def get_absolute_url(self):
return reverse('author-detail', args=[str(self.id)])
def __str__(self):
return '%s, %s' % (self.last_name, self.first_name)
class Meta:
ordering = ['last_name']
当然,该字段不需要是last_name:它可以是任何其他字段。
最后,但并非最不重要的是,你应该按照实际上在数据库上具有索引(唯一或非唯一)的属性/栏位进行排序,以避免性能问题。当然,如果这么少量的书本(和用户!),这里就没有必要(我们可能会让自己提前做太多事情),但是对于未来的项目来说,这是需要考虑的事情。
它看起来是什么样子?
此时,我们应该创建了显示书本列表,和书本详细信息页面所需的所有内容。运行服务器(python3 manage.py runserver),并打开浏览器到 http://127.0.0.1:8000/。
警告: 请还不要点击任何作者、或作者详细信息链接 - 你将在挑战练习中,创建这些链接!
单击所有书籍链接 All books ,以显示书籍列表。
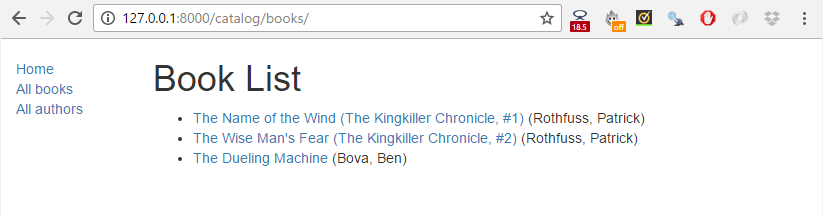
然后点击指向你的某本图书的链接。如果一切设置正确,你应该看到类似下面的屏幕截图。
分页
如果你刚刚获得了一些记录,我们的图书清单页面看起来会很好。但是,当你进入数十或数百条记录的页面时,页面将逐渐花费更长时间加载(并且有太多内容无法合理浏览)。此问题的解决方案,是为列表视图添加分页,减少每页上显示的项目数。
Django 在分页方面,拥有出色的内置支持。更好的是,它内置于基于类的通用列表视图中,因此你无需执行太多操作即可启用它!
视图
打开 catalog/views.py,然后添加下面粗体显示的paginate_by 行。
class BookListView(generic.ListView):
model = Book
paginate_by = 10
通过添加这行,只要你有超过 10 条记录,视图就会开始对它发送到模板的数据,进行分页。使用 GET 参数访问不同的页面 - 要访问第 2 页,你将使用 URL:/catalog/books/?page=2。
模板
现在数据已经分页,我们需要添加对模板的支持,以滚动结果集合。因为我们可能希望在所有列表视图中,都执行此操作,所以我们将以可添加到基本模板的方式,执行此操作。
打开 /locallibrary/catalog/templates/base_generic.html,并复制贴士以下内容区块下面的分页区块(以粗体突出显示)。代码首先检查当前页面上,是否启用了分页。如果是,则它会根据需要,添加下一个和上一个链接(以及当前页码)。
{% block content %}{% endblock %}
{% block pagination %}
{% if is_paginated %}
<div class="pagination">
<span class="page-links">
{% if page_obj.has_previous %}
<a href="{{ request.path }}?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="page-current">
Page {{ page_obj.number }} of {{ page_obj.paginator.num_pages }}.
</span>
{% if page_obj.has_next %}
<a href="{{ request.path }}?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endif %}
{% endblock %}
page_obj 是一个 Paginator 对象,如果在当前页面上使用分页,它将存在。它允许你获取有关当前页面,之前页面,有多少页面等的所有信息。
我们使用 {{ request.path }},来获取用于创建分页链接的当前页面 URL。这很有用,因为它独立于我们正在分页的对象。
就是这样!
它看起来是什么样子的?
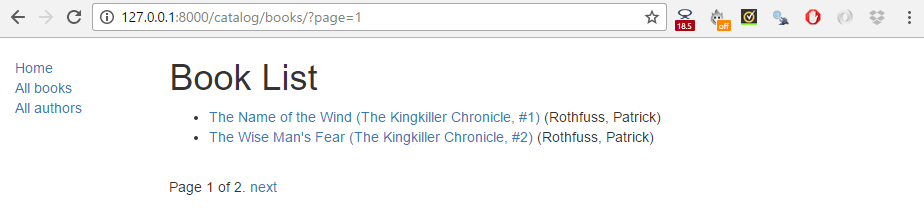
下面的屏幕截图,显示了分页的样子 - 如果你没有在数据库中输入超过 10 个标题,那么你可以通过降低 catalog/views.py 文件中 paginate_by 行指定的数量,来更轻松地测试它。为了得到以下结果,我们将其更改为 paginate_by = 2。
分页链接显示在底部,根据你所在的页面,显示下一个/上一个链接。
挑战自己
本文中的挑战,是创建完成项目所需的作者详细信息视图,和列表视图。这些应在以下 URL 中提供:
catalog/authors/— 所有作者的名单。catalog/author/<id>— 特定作者的详细视图,并具有名为<id>的主键字段
URL 映射器和视图所需的代码,应与我们上面创建的Book列表和详细视图几乎完全相同。模板将有所不同,但会分享类似的行为。
备注:
- 为作者列表页面,创建 URL 映射器之后,还需要更新基本模板中的所有作者 All authors 链接。按照我们更新“所有图书”All books 链接时,所做的相同过程。
- 为作者详细信息页面,创建 URL 映射器之后,还应更新书本详细信息视图模板(/locallibrary/catalog/templates/catalog/book_detail.html),以便作者链接,指向新的作者详细信息页面(而不是一个空的 URL)。该行将更改为添加下面以粗体显示的模板标记。
django
<p> <strong>Author:</strong> <a href="{% url 'author-detail' book.author.pk %}">{{ book.author }}</a> </p>
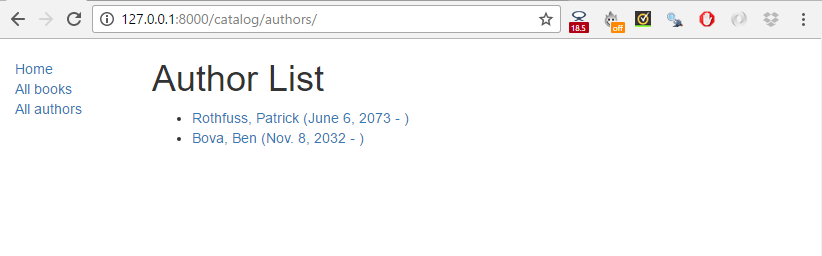
完成后,你的页面应该类似于下面的屏幕截图。
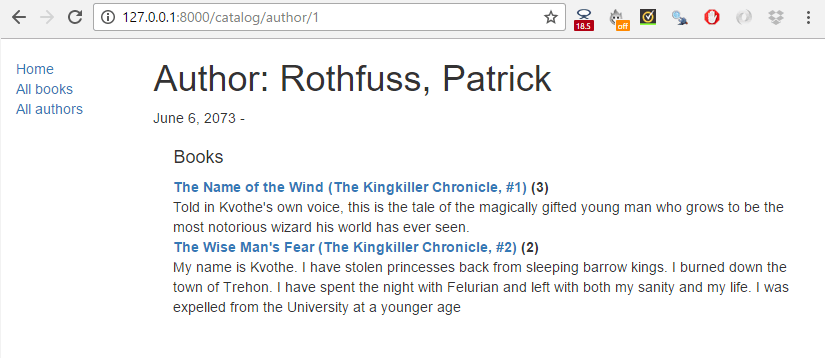
总结
恭喜,我们的图书馆的基本功能现在完成了!
本文中,我们学到如何使用基于类别的通用列表视图与详细视图,并使用它们创建页面,以查看我们的书本和作者。在此过程中,我们了解了与正则表达式匹配的模式,以及如何将数据从 URL 传递到视图。我们还学习了一些使用模板的技巧。最后,我们已经展示了如何对列表视图进行分页,这样即使我们有很多记录,我们也可以管理列表。
在我们的下一篇文章,我们将扩充此图书馆,以支持使用者帐户,并从而演示使用者授权、许可、授权、会话,以及表单。
参见
- Built-in class-based generic views (Django docs)
- Generic display views (Django docs)
- Introduction to class-based views (Django docs)
- Built-in template tags and filters (Django docs).
- Pagination (Django docs)