HTML のデバッグ
HTML を書くのはいいのですが、何かがうまくいかず、コードのどこに誤りがあるのかがわからなくなったらどうしますか。この記事では、 HTML のエラーを探し、修正するのに役立つツールをいくつか紹介します。
| 前提条件: | HTML に、例えば、HTML の始め方、 HTML テキストの基礎、 ハイパーリンクの作成に書かれているようなことに親しんでいること。 |
|---|---|
| 目的: | HTML 内の問題を見つけるためのデバッグ用ツールの基本的な使い方の学習。 |
デバッグは怖くない
ある種のコードを書いているとき、通常はすべてうまくいっているのですが、あるとき恐ろしいことにエラーが発生します。何か間違ったことをしたために、コードが動作しないのです。まったく動作しないか、まったく思い通りに動作しないかのいずれかです。例えば、以下は Rust 言語で書かれた簡単なプログラムをコンパイルした際に報告されたエラーです。
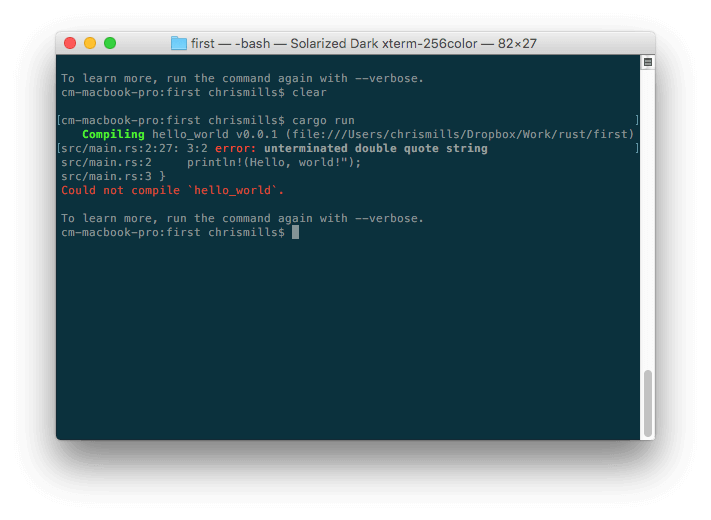 ここで、比較的分かりやすいエラーメッセージがあります。 "unterminated double quote string" (閉じていない二重引用符文字列)。リストを見れば、おそらく論理的に
ここで、比較的分かりやすいエラーメッセージがあります。 "unterminated double quote string" (閉じていない二重引用符文字列)。リストを見れば、おそらく論理的に println!(Hello, world!"); に二重引用符がない可能性があるとわかるでしょう。しかし、プログラムが大きくなるにつれてエラーメッセージはすぐに複雑になり、解釈しにくくなります。簡単な場合でも、 Rust について何も知らない人には少し威圧的に見えるかもしれません。
デバッグを怖がる必要はありません — プログラミング言語やコードの作成、デバッグに慣れるための鍵は、言語とツールの両方に親しんでおくことです。
HTML とデバッグ
HTML は Rust ほど理解するのが複雑ではありません。ブラウザーが解析して結果を表示するまで、 HTML は別の形式にコンパイルされません(解釈されますが、コンパイルはされません)。そして HTML の要素の構文は、Rust、JavaScript、Python のような「実際のプログラミング言語」よりはるかに理解しやすいです。ブラウザーが HTML を解釈する方法は、プログラミング言語が実行される方法よりもずっと寛容で、それは良いことでもあり悪いことでもあります。
寛容なコード
では寛容とはどういうことでしょうか。まあ、一般的にコードで何か間違ったことをするとき、出くわすことになる 2 つの主なタイプのエラーがあります。
- 構文エラー: 上記の Rust エラーのように、コード内のスペルミスで実際にはプログラムが実行されません。言語の構文に精通していて、エラーメッセージが何を意味するのか知っている限り、これらは通常修正が簡単です。
- 論理エラー: これらは、構文は実際には正しいのですが、コードが意図したものではないため、プログラムが正しく実行されないエラーです。エラーの原因を特定するためのエラーメッセージがないため、構文エラーよりも修正が困難です。
HTML 自体は構文エラーに悩まされません。ブラウザーが構文解析エラーを許容して解析するからです。つまり、構文エラーがあってもページは表示されます。ブラウザーには、誤って書かれたマークアップを解釈する方法を決定するための組み込みのルールがあるので、たとえそれが期待したものでなくても、実行することはできます。もちろん、これはまだ問題になる可能性があります。
メモ: ウェブの世界が最初に構築されたとき、 HTML はそれほど厳格には解析されませんでした。これは、構文が絶対的に正しいことを確認するよりも、人々がコンテンツを公開できることのほうが重要であると判断されたためです。ウェブは、最初からもっと厳密なものであったなら、おそらく今日のような人気はなかったでしょう。
アクティブラーニング: 寛容なコードの学習
HTML コードの寛容な性質を学習する時が来ました。
- まず、debug-example のデモをダウンロードしてローカルに保存します。このデモは、調査するために意図的にエラーを含むように書かれています(この HTML マークアップは整形式ではないと呼ばれ、整形式とは対照的です)。
- 次にブラウザーで開きます。 このようなものが表示されるでしょう。
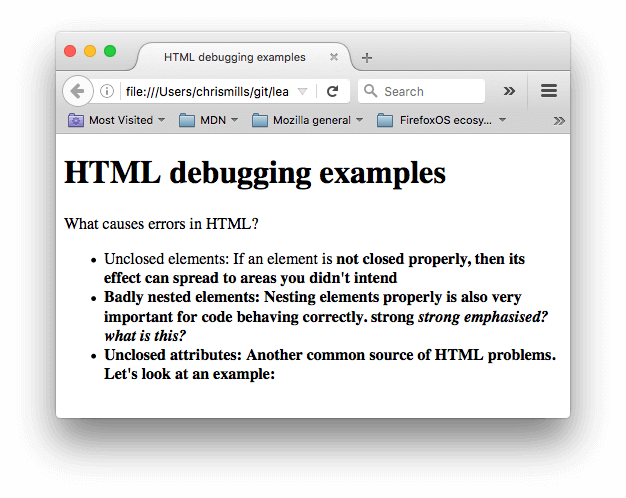
- これはすぐには良く見えません。ソースコードを調べて、問題が解決できるかどうか確認しましょう(本文の内容だけが表示されます)。
html
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - 問題を見てみましょう。
- paragraph と list item 要素には終了タグがありません。上の画像を見ると、ある要素がどこで終わり、別の要素が始まるべきかを推測するのは簡単なので、これはマークアップのレンダリングにあまり悪い影響を与えていないようです。
- 最初の
<strong>要素には終了タグがありません。要素がどこで終了するのか分かりにくいので、もう少し問題があります。実際、残りのテキスト全体が強調されています。 <strong>strong <em>strong emphasized?</strong> what is this?</em>の部分は入れ子構造が間違っています。前の問題もあって、これがどのように解釈されたかを見分けるのは容易ではありません。href属性値に、閉じる二重引用符がありません。これが最大の問題を引き起こしているようです。リンクはまったくレンダリングされていません。
- それでは、ソースコードのマークアップに対して、ブラウザーがレンダリングしたマークアップを見てみましょう。これを行うには、ブラウザーの開発者ツールを使用できます。ブラウザーの開発者ツールの使い方に慣れていない場合は、ブラウザー開発者ツールを見るをちょっと確認してください。
- DOM インスペクターでは、レンダリングされたマークアップがどのように見えるかを見ることができます。
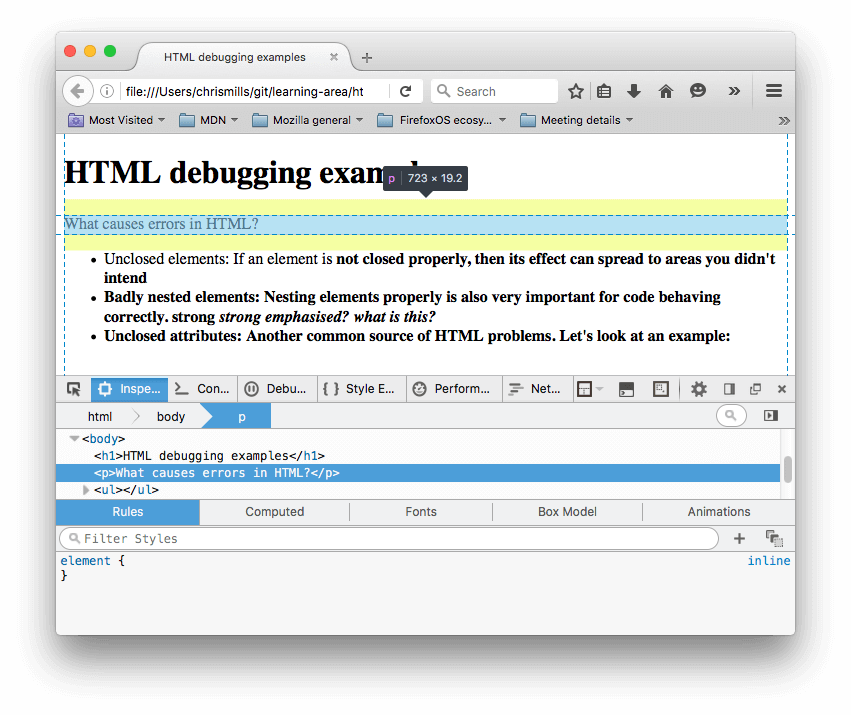
- DOM インスペクターを使用して、ブラウザーが HTML エラーを修正しようとしている方法を確認するためにコードを詳しく調べてみましょう(もちろん Firefox で確認していますが、他の現代のブラウザーでも同じ結果が得られるはずです)。
- 段落とリスト項目には終了タグが付けられています。
- 最初の
<strong>要素がどこで閉じられるべきかは明確ではないので、ブラウザーはそれぞれ別々のテキストブロックをそれぞれの strong タグで、ドキュメントの一番下まで閉じています。 - 不正確な入れ子はブラウザーによってこのように修正されました。
html
<strong> strong <em>strong emphasized?</em> </strong> <em> what is this?</em> - 二重引用符がないリンクは完全に削除されました。 最後のリスト項目は次のようになります。
html
<li> <strong> Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
HTML の検証
上記の例から、HTML が整形式であることを本当に確認したいことがわかります。しかし、どうですか?上のような小さな例では、行を検索してエラーを見つけるのは簡単ですが、巨大で複雑な HTML 文書についてはどうでしょうか。
最良の戦略は、HTML、CSS、およびその他のウェブ技術を定義する仕様書を管理する組織である W3C によって作成および管理されている Markup Validation Service で HTML ページを実行することです。このウェブページは入力として HTML 文書を受け取り、それを通して、 HTML の何が悪いのかを伝えるレポートを提供してくれます。
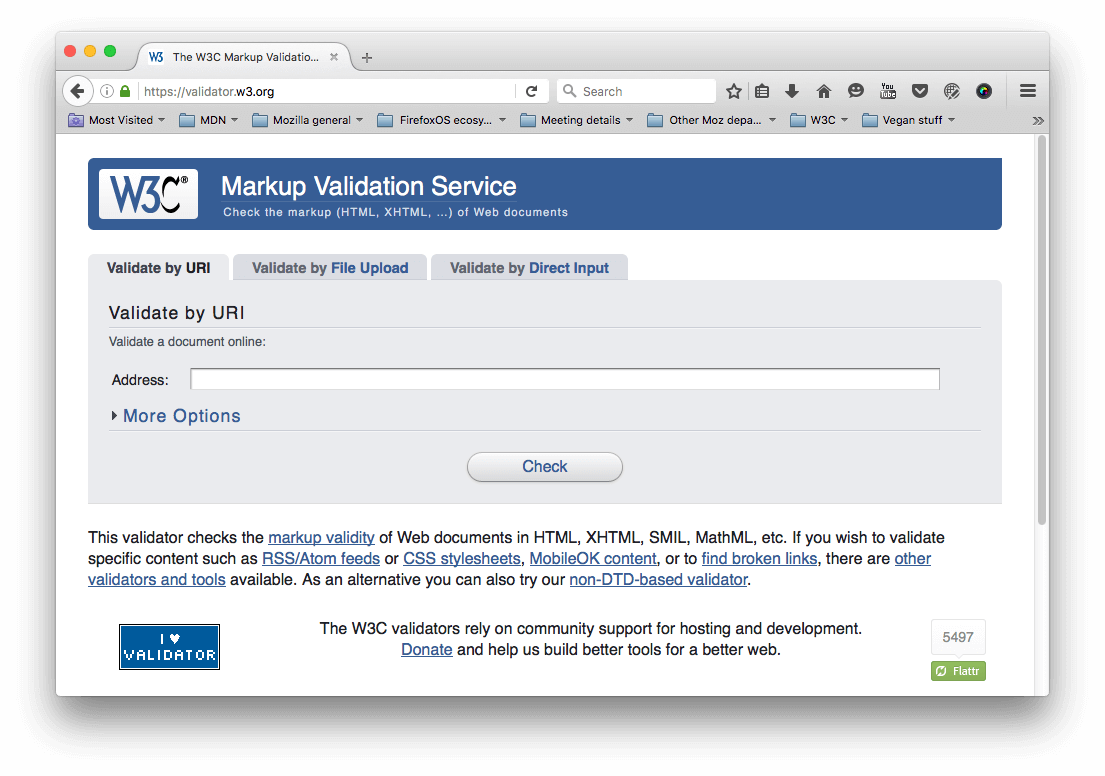
検証する HTML を指定するには、ウェブアドレスを指定するか、HTML ファイルをアップロードするか、または HTML コードを直接入力します。
アクティブラーニング: HTML 文書の検証
サンプル文書でこれを試してみましょう。
- まず、 Markup Validation Service を 1 つのブラウザータブに読み込みます(まだ読み込まれていない場合)。
- Validate by Direct Input タブに切り替えます。
- 本文だけでなく、すべてのサンプル文書のコードをコピーして、 Markup Validation Service に表示される大きなテキスト領域に貼り付けます。
- Check ボタンを押します
これでエラーと他の情報のリストを提供してくれるはずです。
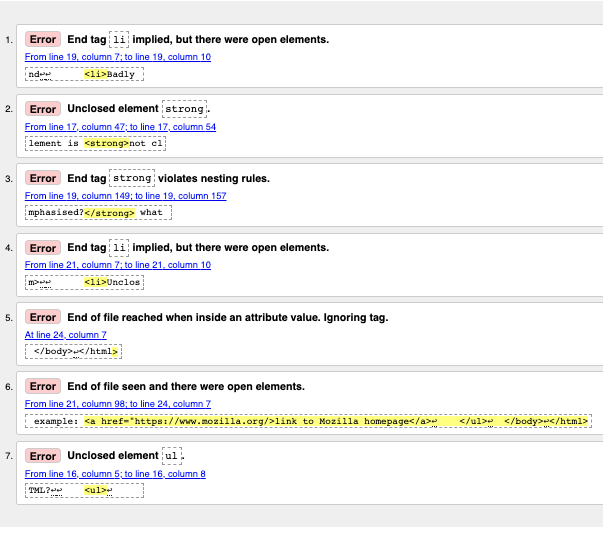
エラーメッセージの解釈
エラーメッセージは通常役に立ちますが、あまり役に立たないこともあります。少し練習すれば、これらを解釈してコードを修正する方法を考え出すことができます。エラーメッセージとその意味を見ていきましょう。各メッセージには行番号と列番号が付いているので、エラーを簡単に見つけることができます。
- "End tag
liimplied, but there were open elements" (2 instances): これらのメッセージは、要素が開いていて閉じる必要があることを示しています。終了タグは暗示されていますが、実際にはありません。行/列情報は、終了タグが実際にあるべき行の後の最初の行を指していますが、これは何が問題なのかを確認するのに十分な手掛かりです。 - "Unclosed element
strong": これは理解するのが本当に簡単です —<strong>要素は閉じられておらず、行/列情報はそれがどこにあるかを指し示しています。 - "End tag
strongviolates nesting rules": これは間違って入れ子になった要素を指摘し、行/列情報はそれがどこにあるかを指摘します。 - "End of file reached when inside an attribute value. Ignoring tag": これはかなり不可解です。ファイルの末尾が属性値の内側に表示されるため、おそらくファイルの末尾近くのどこかに適切に形成されていない属性値があるという事実を意味します。ブラウザーがリンクをレンダリングしないという事実は、どの要素が問題になっているかについての良い手がかりを与えるはずです。
- "End of file seen and there were open elements": これは少しあいまいですが、基本的には適切に閉じる必要がある開いている要素があるという事実を指します。行番号はファイルの最後の数行を指しており、このエラーメッセージには開始要素の例を示すコード行が付いています。
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
メモ: 閉じ引用符が抜けている属性は、文書の残りの部分が属性の内容として解釈されるため、開始要素になる可能性があります。
- "Unclosed element
ul":<ul>要素は正しく閉じられているので、これはあまり役に立ちません。閉じ引用符がないために<a>要素が閉じられていないので、このエラーが発生しています。
すべてのエラーメッセージが何を意味するのかわからない場合でも、心配しないでください — 一度にいくつかのエラーを修正してみることをお勧めします。 それから、どんなエラーが残っているかを示すためにあなたの HTML を再検証することを試みてください。以前のエラーを修正すると他のエラーメッセージも消えてしまうことがあります。つまりはドミノ効果で、単一の問題が原因でいくつかのエラーが発生することがあるということです。
出力に次のバナーが表示されたら、エラーがすべて解決したことがわかります。
![]()